导语:模糊测试是现在最常用的漏洞挖掘技术,Fuzzer将半随机输入喂到到测试程序,目的是找到触发错误的输入。模糊测试在查找C或C ++程序中的内存破坏漏洞时特别有用。 通常情况下,建议选择一个众所周知但很少探索的库,这个库在解析时很重要。
模糊测试是现在最常用的漏洞挖掘技术,Fuzzer将半随机输入喂到到测试程序,目的是找到触发错误的输入。模糊测试在查找C或C ++程序中的内存破坏漏洞时特别有用。
通常情况下,建议选择一个众所周知但很少探索的库,这个库在解析时很重要。历史上,像libjpeg,libpng和libyaml这样的东西都是完美的目标。如今找到一个好目标更难 – 一切似乎都已经被模糊化了。这是好事!我猜软件越来越好了!我没有选择用户空间目标,而是选择了Linux内核netlink机器。
Netlink是一个Linux内核工具,它用于配置网络接口,IP地址,路由表等。这是一个很好的fuzzing 目标:它是内核的一个小模块,并且生成畸形有效消息相对比较容易。最重要的是,我们可以在此过程中学到很多关于Linux内核的知识。
在这篇文章中,我将使用AFL模糊器,将netlink shim程序与自定义Linux内核相对应,所有这些都在KVM虚拟机中运行。
历史上的内核Fuzzing技术
我们将要使用的技术被称为“覆盖引导模糊测试”。有很多以前的文献:
· Dan Guido 的智能模糊革命,以及LWN关于它的文章
· Mateusz“j00ru”Jurczyk的有效文件格式模糊测试
· honggfuzz是一个现代化的,功能丰富的覆盖面引导的fuzzer
很多人过去都在Fuzzing Linux内核:
· 由Dmitry Vyukov 创建的syzkaller(又名syzbot)是一个非常强大的CI风格的持续运行的内核模糊器,它已经发现了数百个漏洞。
· 三位一体的模糊器
我们将使用AFL,可能是大家最喜欢的模糊器。AFL由MichałZalewski撰写。它以其易用性,速度和非常好的变异逻辑而闻名,这是开始模糊测试之旅的完美选择!
如果您想了解有关AFL的更多信息,请参阅几个文件:
· 历史笔记
· 技术白皮书
· 自述
覆盖引导的模糊测试
覆盖引导的模糊测试基于反馈回路的原理:
· 模糊测试选择最有希望的测试用例
· 模糊测试将测试变为大量新的测试用例
· 目标代码运行变异的测试用例,并报告代码覆盖率
· 模糊器根据报告的覆盖范围计算得分,并使用它来确定有效的变异测试的优先级并删除冗余的测试
例如,假设输入测试是“hello”。Fuzzer可能会将其变为多种测试,例如:“hEllo”(位翻转),“hXello”(字节插入),“hllo”(字节删除)。如果这些测试中的任何一个将产生有趣的代码覆盖,那么它将被优先化并用作下一次测试的基础。
有关如何完成突变以及如何有效地比较数千个程序运行的代码覆盖率报告的细节是模糊测试的秘诀,阅读AFL的技术白皮书,可以了解更多细节。
通常,在使用AFL时,我们需要检测目标代码,以便以AFL兼容的方式报告覆盖范围。但我们想要Fuzzing 内核!我们不能只用“afl-gcc”重新编译它!。我们将准备一个二进制文件,让AFL认为它是用它的工具编译的。这个二进制文件将报告从内核中提取的代码覆盖率。
内核代码覆盖率
内核至少有两个内置的覆盖机制–GCOV和KCOV:
KCOV的设计考虑了模糊测试,因此我们将使用它。
使用KCOV非常简单。我们必须使用正确的设置编译Linux内核。首先,启用KCOV内核配置选项:
cd linux ./scripts/config \ -e KCOV \ -d KCOV_INSTRUMENT_ALL
KCOV能够记录整个内核的代码覆盖率。可以使用KCOV_INSTRUMENT_ALL选项进行设置。有个缺点是,它会减慢我们不想分析的内核部分,并且会在Fuzzing 中引入噪声(降低“稳定性”)。对于初学者,让我们禁用KCOV_INSTRUMENT_ALL并有选择地在实际想要分析的代码上启用KCOV。
我们专注于Fuzzing netlink,所以在整个“net”目录树上启用KCOV:
find net -name Makefile | xargs -L1 -I {} bash -c 'echo "KCOV_INSTRUMENT := y" >> {}'
在一个理想环境中,我们只能为真正感兴趣的几个文件启用KCOV。但是netlink处理遍及整个网络堆栈代码,现在没有时间进行微调。
有了KCOV,将增加报告内存损坏错误的可能性。最重要的是KASAN,使用该集合,可以编译我们的KCOV和KASAN启用的内核。
我们将以kvm运行内核,所以需要切换一下:
./scripts/config \ -e VIRTIO -e VIRTIO_PCI -e NET_9P -e NET_9P_VIRTIO -e 9P_FS \ -e VIRTIO_NET -e VIRTIO_CONSOLE -e DEVTMPFS ...
如何使用KCOV
KCOV非常容易上手。代码覆盖率会记录在每个进程的数据结构中,就是说必须在用户空间进程中启用和禁用KCOV,并且无法记录非任务事项的覆盖范围,比如最常见的中断处理。
KCOV将数据发送到缓冲区,然后就可以使用一个简单的ioctl启用&禁用它:
ioctl(kcov_fd, KCOV_ENABLE, KCOV_TRACE_PC); /* profiled code */ ioctl(kcov_fd, KCOV_DISABLE, 0);
缓冲区会包含启用KCOV内核代码的所有基本块的%rip值列表。
要读取缓冲区,运行如下代码:
n = __atomic_load_n(&kcov_ring[0], __ATOMIC_RELAXED);
for (i = 0; i < n; i++) {
printf("0x%lx\n", kcov_ring[i + 1]);
}
使用addr2line工具可以将%rip解析为特定的代码行。
将KCOV喂到AFL中
AFL需要一个特制的可执行文件,但我们想要知道内核代码覆盖率。我们先了解一下AFL的工作原理。
AFL设置一个64K 8位数字的数组。该存储器区域称为“shared_mem”或“trace_bits”,并与trace的程序共享这块存储区域。数组中的每个字节都可以被认为是检测代码中特定对(branch_src,branch_dst)的命中计数器。
AFL更更多的是使用随机分支,而不是重用%rip值来识别基本块,主要是为了增加熵,我们希望数组中的命中计数器均匀分布。
AFL使用的算法如下:
cur_location = <COMPILE_TIME_RANDOM>; shared_mem[cur_location ^ prev_location]++; prev_location = cur_location >> 1;
在使用KCOV的情况下,没有每个分支的编译时随机值。但是,我们可以使用哈希函数从KCOV记录的%rip生成统一的16位数。
下面代码显示了如何将KCOV报告提供给AFL“shared_mem”数组:
n = __atomic_load_n(&kcov_ring[0], __ATOMIC_RELAXED);
uint16_t prev_location = 0;
for (i = 0; i < n; i++) {
uint16_t cur_location = hash_function(kcov_ring[i + 1]);
shared_mem[cur_location ^ prev_location]++;
prev_location = cur_location >> 1;
}
从AFL读取测试数据
现在需要实际编写核心netlink接口的测试代码!首先,我们需要从AFL读取输入数据。默认情况下,AFL将测试用例发送到stdin:
/* read AFL test data */ char buf[512*1024]; int buf_len = read(0, buf, sizeof(buf));
Fuzzing netlink
然后我们需要将此缓冲区发送到netlink套接字,使用前5个字节的输入作为netlink协议和组ID字段。这将允许AFL找出并猜测这些字段的正确值。
netlink测试代码(简化):
netlink_fd = socket(AF_NETLINK, SOCK_RAW | SOCK_NONBLOCK, buf[0]); struct sockaddr_nl sa = { .nl_family = AF_NETLINK, .nl_groups = (buf[1] <<24) | (buf[2]<<16) | (buf[3]<<8) | buf[4], }; bind(netlink_fd, (struct sockaddr *) &sa, sizeof(sa)); struct iovec iov = { &buf[5], buf_len - 5 }; struct sockaddr_nl sax = { .nl_family = AF_NETLINK, }; struct msghdr msg = { &sax, sizeof(sax), &iov, 1, NULL, 0, 0 }; r = sendmsg(netlink_fd, &msg, 0); if (r != -1) { /* sendmsg succeeded! great I guess... */ }
为了提升Fuzzing速度,我们将它包装在一个模仿AFL“fork服务器”逻辑的短循环中。
AFL-to-KCOV的结果代码如下所示:
forksrv_welcome(); while(1) { forksrv_cycle(); test_data = afl_read_input(); kcov_enable(); /* netlink magic */ kcov_disable(); /* fill in shared_map with tuples recorded by kcov */ if (new_crash_in_dmesg) { forksrv_status(1); } else { forksrv_status(0); } }
运行自定义内核
如何实际运行构建的自定义内核。有三种选择:
“native”:您以在服务器上完全启动构建的内核并在本机Fuzzing它。这种方法速度很快,但也很有问题。如果Fuzzing成功找到了crash,电脑可能会蓝屏崩溃,可能会丢失测试数据。
“uml”:可以将内核配置为以用户模式运行。运行UML内核不需要任何权限,内核只运行用户空间进程。UML有一个问题是,它不支持KASAN,因此对于内存破坏漏洞的挖掘就那么有用了。
“kvm”:可以使用kvm在虚拟机环境中运行自定义内核,这就是我们要做的。
在KVM环境中运行自定义内核的最简单方法之一是使用“virtme”脚本。有了它们,我们可以避免创建专用的磁盘映像或分区,只需共享主机文件系统。
这就是我们运行代码的方式:
virtme-run \ --kimg bzImage \ --rw --pwd --memory 512M \ --script-sh "<what to run inside kvm>"
构建输入语料库
每个Fuzzer都需要精心设计的测试用例作为输入,以引导使程序产生突变输出。测试用例应该简短,并尽可能覆盖大部分代码。
这是我们的输入语料库:
mkdir inp echo "hello world" > inp/01.txt
如何编译和运行的说明都在我们的github上的README.md中。
virtme-run \ --kimg bzImage \ --rw --pwd --memory 512M \ --script-sh "./afl-fuzz -i inp -o out -- fuzznetlink"
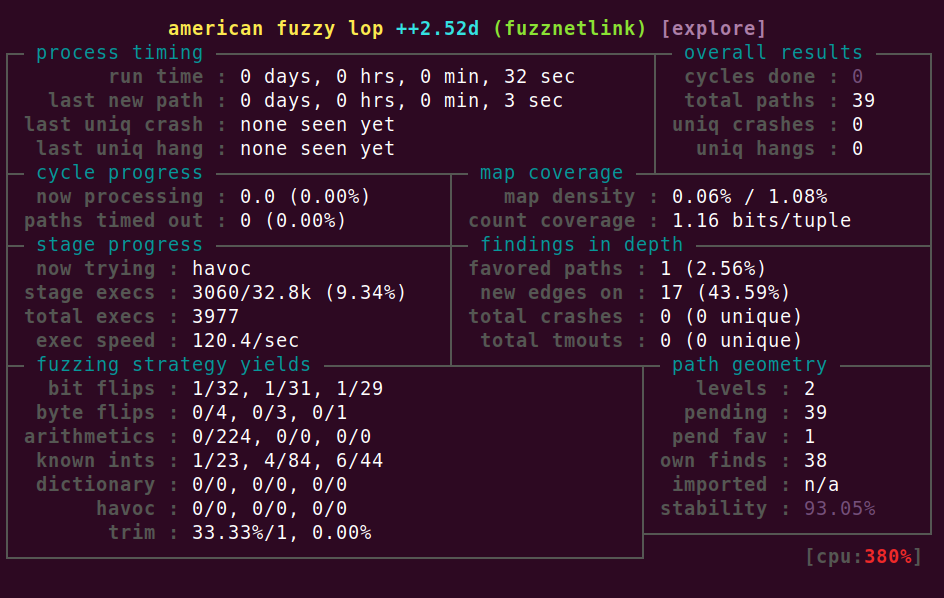
运行后,AFL就开始Fuzzing了:

总结
在这篇文章中我们没有提到:
· AFL shared_memory设置的详细信息
· 运行AFL持久模式
· 关于如何读取dmesg(/ dev / kmsg)以查找内核crash的技巧
· 在KVM之外运行AFL,以获得速度和稳定性
但是实现了我们的目标,我们针对内核建立了一个基本但仍然有用的Fuzzer。最重要的是:可以重复使用相同的机制来Fuzzing Linux子系统的其他部分,比如从文件系统到bpf验证程序。
我有一些感悟:正确的模糊测试绝对不是启动Fuzzer后无所事事地等待崩溃。总有一些东西需要改进,调整和重新实现。Mateusz Jurczyk在之前演讲开头的一句话引起了我的共鸣:“Fuzzing很容易学,但很难掌握。”
如有侵权请联系:admin#unsafe.sh