再次捕获云上在野容器攻击,TeamTNT黑产攻击方法揭秘 文章中提到一个内核rootkit-Diamorphine[1]新型eBPF后门boopkit的原理分析与演示[2] 也提到基于 ebpf的ro 2022-7-31 13:7:24 Author: leveryd(查看原文) 阅读量:46 收藏
再次捕获云上在野容器攻击,TeamTNT黑产攻击方法揭秘 文章中提到一个内核rootkit-Diamorphine[1]
新型eBPF后门boopkit的原理分析与演示[2] 也提到基于 ebpf的rootkit[3]
本文简要分析这两个rootkit在"进程隐藏"上实现的区别。
特别因为是eBPF只能通过["helper functions"](https://ebpf.io/what-is-ebpf#helper-calls ""helper functions"")调用内核能力,而不能直接调用内核函数、修改内核数据结构,所以我好奇eBPF后门怎么实现"进程隐藏"。
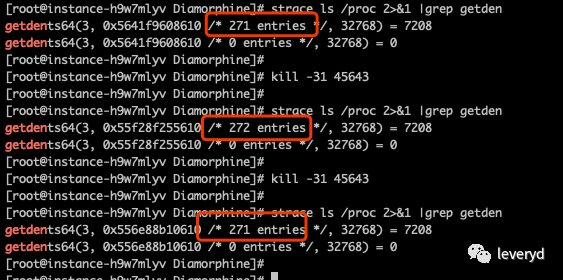
通过修改__sys_call_table,hook了kill、getdents64系统调用。
用户在调用kill系统调用时,rootkit在收到信号"SIGMODINVIS"(头文件中可以看到是31)后,就会执行两步:
for_each_process找到进程task_struct 修改task_struct的flags
// diamorphine.c
hacked_kill(pid_t pid, int sig)
{
...
struct task_struct *task;
switch (sig) {
case SIGINVIS:
if ((task = find_task(pid)) == NULL) // 根据pid找到task_struct实例
return -ESRCH;
task->flags ^= PF_INVISIBLE;
break;
用户在getdents64系统调用查看目录信息时,rootkit会修改返回给用户的目录信息。
hacked_getdents64(unsigned int fd, struct linux_dirent64 __user *dirent,
unsigned int count)
{
int ret = orig_getdents64(fd, dirent, count), err; // 调用原先的getdents64函数
... kdirent = kzalloc(ret, GFP_KERNEL); // 申请ret大小的内核内存
...
err = copy_from_user(kdirent, dirent, ret); // 将"目录信息"复制一份
...
while (off < ret) {
dir = (void *)kdirent + off;
if ((!proc &&
(memcmp(MAGIC_PREFIX, dir->d_name, strlen(MAGIC_PREFIX)) == 0)) // 文件以MAGIC_PREFIX开头
|| (proc &&
is_invisible(simple_strtoul(dir->d_name, NULL, 10)))) { // /proc/${pid} 被标记成需要隐藏
...
}
...
err = copy_to_user(dirent, kdirent, ret); // 将修改后的"目录信息"复制给用户
测试后,就会发现rootkit会影响/proc目录中是否可以看到进程目录。
实际上是rootkit影响了getdents64系统调用的结果
ps命令也是读/proc目录来获取进程信息的,所以rootkit影响ps命令结果
所以这个lkm rootkit是通过修改task_struct的flags字段来给进程打个标记,等getdents64时会根据标记判断是不是要修改目录信息。
eBPF程序不能直接修改内核数据,那eBPF后门是怎么做"进程隐藏"的呢?
getdents64系统调用可以用来获取目录信息,man 2 getdents可以知道第二个指针参数指向"目录条目"buffer
int getdents64(unsigned int fd, struct linux_dirent64 *dirp,
unsigned int count);
"目录条目"数据结构如下,因为有"柔性数组",所以用d_reclen记录了大小,这样就可以在"目录条目"buffer中定位到下一个"目录条目"。
struct linux_dirent64 {
ino64_t d_ino; /* 64-bit inode number */
off64_t d_off; /* 64-bit offset to next structure */
unsigned short d_reclen; /* Size of this dirent */ 当前"目录条目"的大小
unsigned char d_type; /* File type */
char d_name[]; /* Filename (null-terminated) */ 柔性数组
};
pr0be.safe.c 注释写得很清楚,通过增大"目标进程所属的目录条目的前一个目录条目"的d_reclen值,使得用户程序在遍历*dirp结果时,就会跳过"目标进程所属的目录条目"。
SEC("tp/syscalls/sys_exit_getdents64")
int handle_getdents_patch(struct trace_event_raw_sys_exit *ctx) {
...
// Unlink target, by reading in previous linux_dirent64 struct,
// and setting it's d_reclen to cover itself and our target.
// This will make the program skip over our folder.
...
// Attempt to overwrite
short unsigned int d_reclen_new = d_reclen_previous + d_reclen;
long ret = bpf_probe_write_user(&dirp_previous->d_reclen, &d_reclen_new,
sizeof(d_reclen_new));
因为&dirp_previous->d_reclen是用户空间地址,而不是内核空间地址,所以ebpf可以用bpf_probe_write_user helper functions 修改dirp地址中的数据。
案例中的lkm rootkit和ebpf rootkit都是通过修改getdents64系统调用中dirp地址指向的内容,使得查看/proc目录信息时,看不到进程信息。
根据帖子[4]知道,利用ebpf修改系统调用的参数值或返回值时有很大的限制。因为dirp是一个用户空间地址,所以ebpf程序可以用bpf_probe_write_user修改此地址的内容。
参考资料
内核rootkit-Diamorphine: https://github.com/m0nad/Diamorphine
[2]新型eBPF后门boopkit的原理分析与演示: https://www.cnxct.com/ebpf-rootkit-how-boopkit-works/
[3]ebpf的rootkit: https://github.com/kris-nova/boopkit
[4]帖子: https://stackoverflow.com/questions/43003805/can-ebpf-modify-the-return-value-or-parameters-of-a-syscall
如有侵权请联系:admin#unsafe.sh