2019年9月19号,DOMPurify(XSS过滤器)发布了新版本,新版本修复了本文即将提到的绕过问题。抛砖引玉,因此在本文中,我首先介绍DOMPurify的大体情况以及工作原理,进而引出绕过原理。如果读者已经充分掌握DOMPurify和mXSS的原理-建议你直接跳到Chromium(和Safari)中的mXSS这一部分。
许多web应用程序,以编辑器的形式,允许用户使用一些特殊的文本格式(例如,粗体,斜体等等)。这个功能在博客,邮件当中使用甚广。这里出现的主要安全问题就是有些不法用户可能输入一些恶意HTML/JavaScript从而引入XSS。因此,这类允许用户进行个性化输入的应用程序的创建者就面临一个很头疼的问题:如何确保用户的输入的HTML是安全的,从而不会引起不必要的XSS。
这就是为什么需要HTML过滤器的原因。HTML过滤器的主要目的是揪出不可信的输入,对其进行过滤,并生成安全的HTML(过滤所有危险标签的HTML)。
过滤器通常通过解析输入来进行过滤(从JavaScript中有几种方法可以实现这一点,例如使用 DOMParser.prototype.parseFromString方法),然后,过滤器本身有一个安全的元素和属性的列表,遍历DOM树然后删除列表中没有包括的内容(简要的介绍了一下原理,真正的原理比这个复杂多了)。
因此,假设我们有一个具有以下安全列表的过滤器:
元素: <div>, <b>, <i> and <img>.
属性: src.接着,用户输入以下HTML:
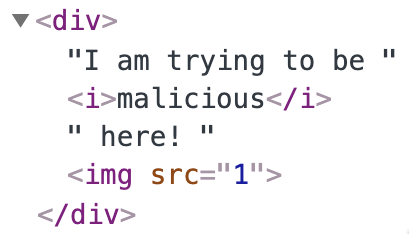
<div>I am trying to be <i>malicious</i> <u>here</u>! <img src=1 onerror=alert(1)></div>解析之后,获得以下DOM树:

对比一下安全列表,需要删除两处不包含在列表里的元素及属性
<u>
onerror因此,遍历DOM树并执行过滤操作之后,得到以下结果:
于是现在就产生了一个“安全的”DOM树,其中过滤了所有不存在安全列表的元素或属性。因此,过滤后就变成了以下字符串:
<div>I am trying to be <i>malicious</i> here! <img src="1"></div>但现在就万事大吉了吗?我们就可以认为这是一个安全的HTML片段了吗?我只能说这基本上算是安全的,但别忘了还有一个重要的漏洞——突变XSS。
关于突变XSS的定义,可以追溯于Mario Heiderich等人于2013年发表的一篇论文“ mXSS Attacks: Attacking well-secured Web-Applications by using innerHTML Mutations.”在下一部分中,我将简要介绍什么是突变XSS以及怎样绕过DOMPurify。
innerHTML是DOM元素中一种非常容易使用的方法,利用该方法我们输入一些HTML,它就会被自动解析并插入到DOM树中。
element.innerHTML = '<u>Some <i>HTML'"="的右侧部分将被自动解析并作为element的子元素插入到DOM树中。但是,innerHTML的问题是浏览器可以改变我们想要插入的字符串。例如,如果我尝试读取element.innerHTML,我会得到以下结果:

在赋值给innerHTML之后,我读取后却得到一个不同的值。我早已料到这种情况,用户可以输入破损的HTML,但浏览器必须要修复它。
但我们发现有时输入会发生几次变异。康一康以下表达式:
element.innerHTML = element.innerHTML乍一看,将innerHTML赋给自己应该没有关系。但这里就是问题所在,由于浏览器的bug,突变XSS就产生了。
我在当前版本的Chrome(77)中发现了一个新的突变XSS向量,我就可以利用突变XSS绕过DOMPurify。
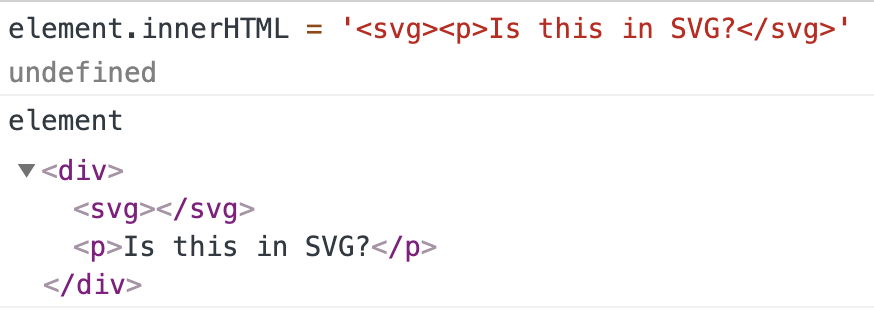
首先分配一个<svg>标签,<p>是它的子标签。但是从DOM树中我们可以发现,<p>元素实际上“跳出”了<svg>。发生这种情况的主要原因是<p>不是<svg>中的有效标签,因此浏览器会在结束<svg>后打开<p>。
但是,让我们看看当我尝试在SVG中放置结束</p>标记时会发生什么:
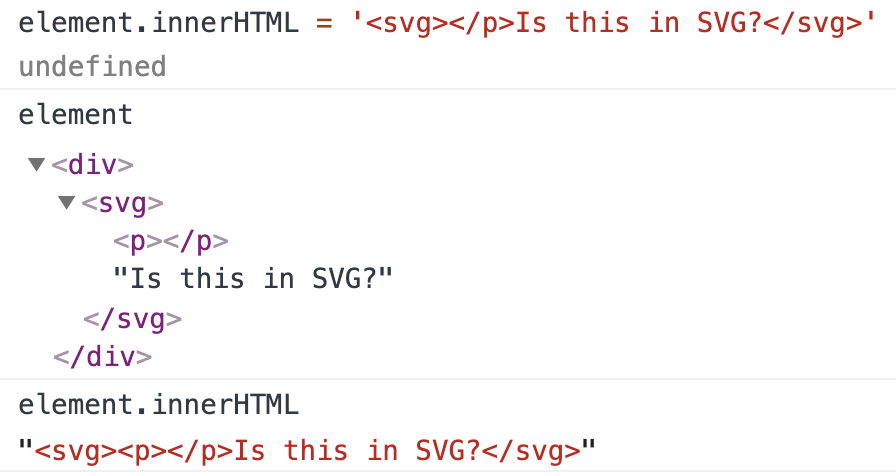
<p>元素现在是<svg>的子元素,且Chrome自动添加了开始<p>标签。这意味着如果我试图将innerHTML赋值给它本身,它将发生变异!

因此,<svg></p>的payload是突变XSS的基础,因为它在分配给innerHTML时会发生变异;最初位于<svg>内的内容会跳出。剩下的步骤是如何利用它。
试一试将以下字符串分配给DOM元素的innerHTML:
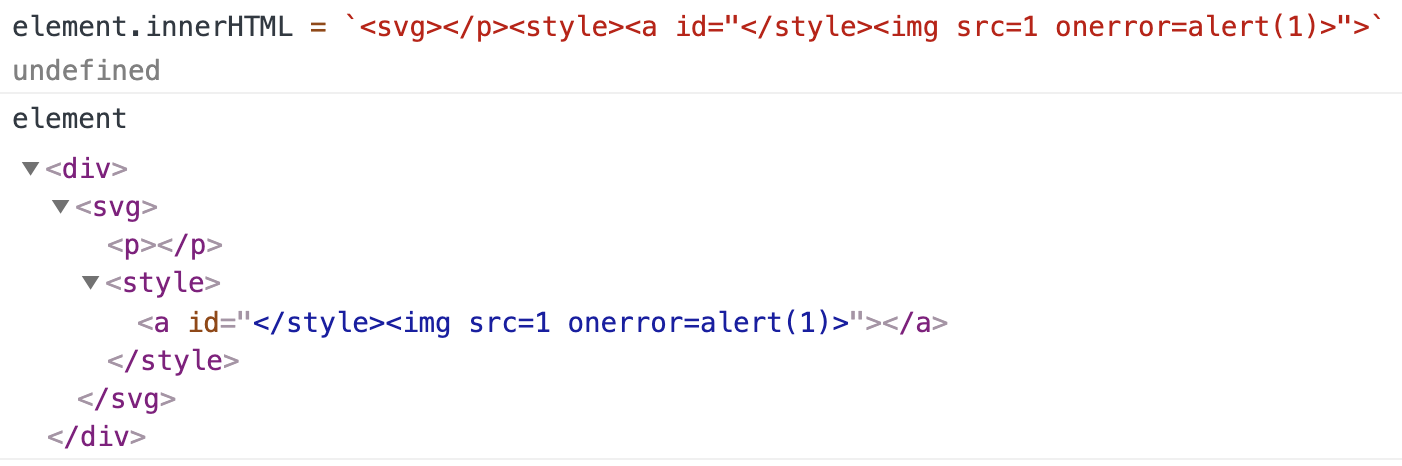
<svg></p><style><a id="</style><img src=1 onerror=alert(1)>">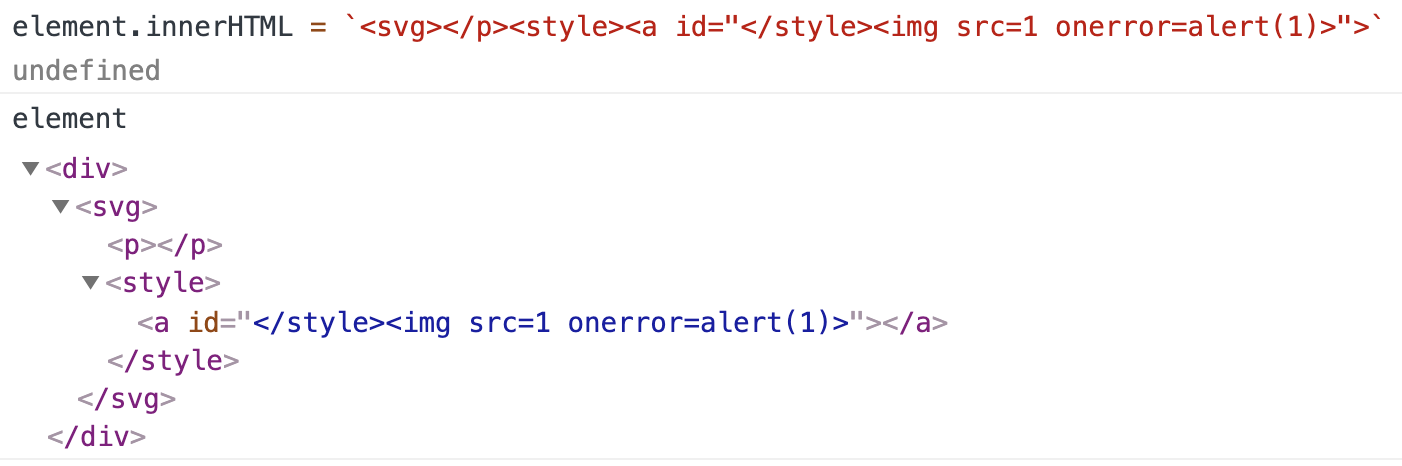
这个DOM片段本身没有什么问题。默认配置下,DOMPurify允许所有标签(<div>,<svg>,<p>,<style>和<a>)和属性id。所以它不会改变代码中的任何内容。但是,当我们尝试将innerHTML分配给自身时,…
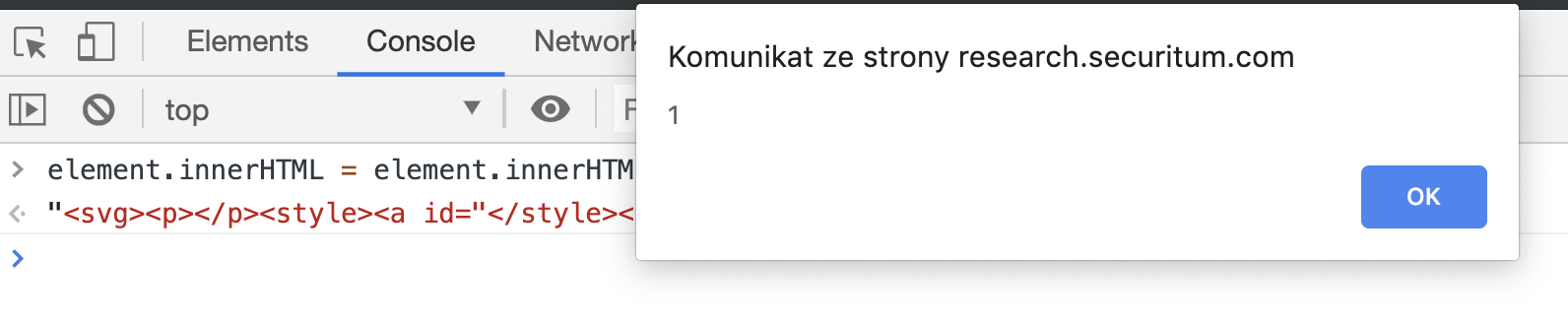
突然的alert!
当你在HTML中打开<svg>时,浏览器的解析规则会发生变化,解析规则趋于XML解析而不是HTML解析。主要区别在于HTML中的某些标签在从文本反序列化时不能有子标签。例如<style>。如果查看HTML规范,我们会发现它的内容模型是Text。即使您尝试将元素放在<style>中,它也会被视为文本:
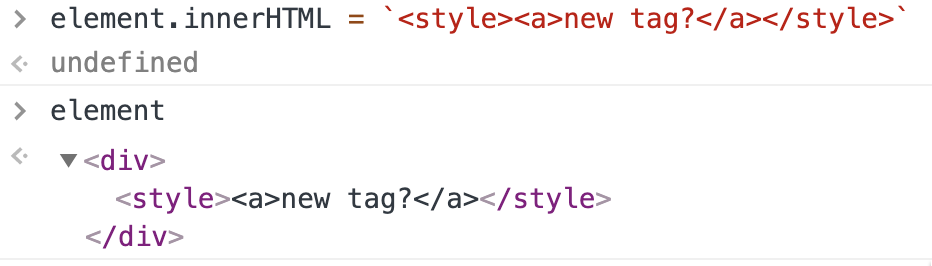
对于SVG来说,事情并非如此。让我们继续用上面的例子,但<style>是<svg>的子标签:
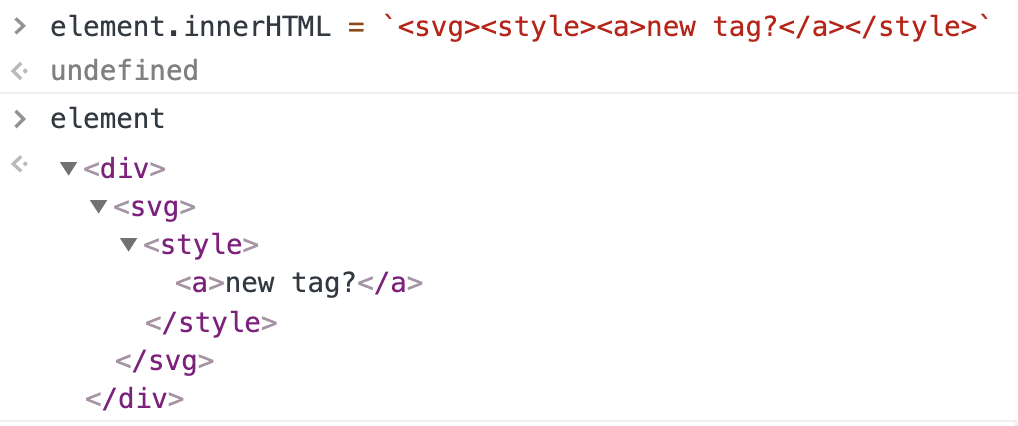
<style>有了子元素
现在让我们看看DOMPurify的示例:

在这种情况下,浏览器假定</p>和<style>都是<svg>的子元素,这间接导致<a>元素是<style>的子元素。
但是,代码发生了一点变异,现在<svg>中也有一个<p>。该代码理论上是安全的,因为危险的<img>元素实际上在id属性的值内。
但是,当我们尝试将结果HTML分配给innerHTML时,代码将变异为以下形式:

现在<svg>元素立即结束,后面的一切代码都是普通的HTML。这意味着<style>——</style>,包含onerror属性的<img>标签被写入DOM树。

Bingo!这就是Chrome中的mXSS被滥用来绕过DOMPurify。同样的技巧有可能拿来绕过其他过滤器。
读者可以在我准备的jsbin中大施拳脚。
在这篇文章中,我介绍了一个由于Chrome存在的突变XSS向量从而绕过DOMPurify的方法。成因是<svg></p>被浏览器重写为<svg><p></svg>,然后在将其分配给innerHTML后重写为<svg></svg><p></p>。最初的HTML解析假定某些元素在<svg>内,而在随后的解析中,这些元素在<svg>之外,从而允许添加任意HTML标签。
<svg></p><style><a id="</style><img src=1 onerror=alert(1)>">在报告了绕过DOMPurify之后,我又发现了很多问题。首先,mXSS不仅可以在Chrome中使用,也可以在Safari中使用。其次,它还有几个变体:
可以使用<math>代替<svg>,</br>代替</p>
如果你正在使用DOMPurify,你应该立即将其更新到2.0.1或更高版本。如果你不想升级版本的话,你也可以禁用<math>和<svg>达到同样效果:
DOMPurify.sanitize(input, {
FORBID_TAGS: ['svg', 'math']
});原文:https://research.securitum.com/dompurify-bypass-using-mxss/如有侵权请联系:admin#unsafe.sh