导语 | 腾讯云加社区精品内容栏目《云荐大咖》,特邀行业佼者,聚焦前沿技术的落地与理论实践,持续为您解读云时代热点技术,探秘行业发展新机。
一、带着疑问看历史
提起链路追踪,大部分人都会想起Zipkin、Jaeger、Skywalking这些已经比较成熟的链路追踪开源软件以及Opentelemetry、OpenTracing、OpenCensus这些开源标准。虽然实现各有差异,但是使用各种软件、标准和实现组合搭建出来的不同的链路追踪系统,却有着许多相类似的地方。
例如这些链路追踪系统都需要在调用链路上传播元数据。他们对元数据内容的定义也大同小异,链路唯一的trace id,关联父链路的parent id,标识自身的span id这些。他们都是异步分散上报采集的追踪信息,离线的聚合聚合追踪链路。他们都有链路采样等等。
链路追踪系统架构和模型的设计看着都是如此相似,我不禁会产生一些疑问:开发者在设计链路追踪的时候,想法都是这么一致吗?为什么要在调用链路传递元数据?元数据的这些信息都是必要的吗?不侵入修改代码可以接入到链路追踪系统吗?为什么要异步分散上报,离线聚合?设置链路采样有什么用?
带着各种各样的问题,我找到这些众多链路追踪软件的灵感之源——《Google Dapper》论文,并且拜读了原文以及相关的引用论文。这些论文逐渐解开了我心中的疑惑。
二、黑盒模式探索
早期学术界对分布式系统链路状态检测的探索,有一派的人们认为分布式系统里面的每个应用或者中间件,应该是一个个黑盒子,链路检测不应该侵入到应用系统里面。那个时候Spring还没被开发出来,控制反转和切面编程的技术也还不是很流行,如果需要侵入到应用代码里面,需要涉及到修改应用代码,对于工程师来说额外接入门槛太高,这样的链路检测工具就会很难推广开来。
如果不允许侵入应用里面修改代码,那就只能够从应用的外部做手脚,获取并记录链路信息了。而由于黑盒的限制,链路信息都是零散的无法串联起来。如何把这些链路串联起来成了需要解决的问题。
《Performance Debugging for Distributed Systems of Black Boxes》这篇论文发表于2003年,是对黑盒模式下的调用链监测的探索,文中提出了两种寻找链路信息的算法。
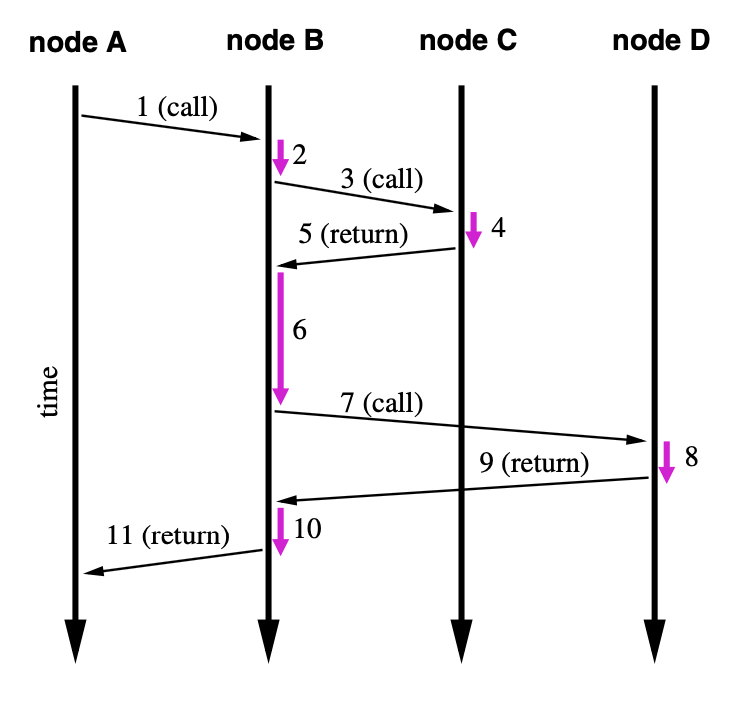
第一种算法称为“嵌套算法”,首先是通过生成唯一id的方式,把一次跨服务调用的请求(1 call)链路与返回(11 return)链路关联再一起形成链路对。然后再利用时间的先后顺序,把不同往返链路对做平级关联或上下级关联(参考图1)。
图1
如果应用是单线程情况,这种算法但是没有什么问题。生产的应用往往是多线程的,所以使用这种方法无法很好的找到链路间对应关系。虽然论文提出了一种记分板惩罚的方法可以对一些错误关联的链路关系进行除权重,但是这种方法对于一些基于异步RPC调用的服务,却会出现一些问题。
另外一种算法称为“卷积算法”,把往返链路当成独立的链路,然后把每个独立链路对当成一个时间信号,使用信号处理技术,找到信号之间的关联关系。这种算法好处是能够出使用在基于异步RPC调用的服务上。但是如果实际的调用链路存在回环的情况,卷积算法除了能够得出实际的调用链路,还会得出其他调用链路。例如调用链路A->B->C->B->A,卷积算法除了得出其本身调用链路,还会得出A->B->A的调用链路。如果某个节点在一个链路上出现次数多次,那么这个算法很可能会得出大量衍生的调用链路。
在黑盒模式下,链路之间的关系是通过概率统计的方式判断链路之间的关联关系。概率统计始终是概率,没办法精确得出链路之间的关联关系。
三、另一种思路
怎么样才能够精确地得出调用链路之间的关系呢?下面这篇论文就给出了一些思路与实践。
《Pinpoint: Problem Determination in Large,Dynamic Internet Services》
注:此Pinpoint非github上的pinpoint-apm
这篇论文的研究对象主要是拥有不同组件的单体应用,当然相应的方法也可以扩展到分布式集群中。在论文中Pinpoint架构设计主要分为三部分。参考图2,其中Tracing与Trace Log为第一部分,称为客户端请求链路追踪(Client Request Trace),主要用于收集链路日志。Internal F/D、External F/D和Fault Log为第二部分,是故障探测信息(Failure Detection),主要用于收集故障日志。Statistical Analysis为第三部分,称为数据聚类分析(Data Clustering Analysis),主要用于分析收集进来的日志数据,得出故障检测结果。
图2
Pinpoint架构中,设计了一种能够有效用于数据挖掘分析方法的数据。如图3所示,每个调用链路作为一个样本数据,使用唯一的标识request id标记,样本的属性记录了这个调用链路所经过的程序组件(Component)以及故障状态(Failure)。
图3
为了能够把每次调用的链路日志(Trace Logs)和故障日志(Fault Logs)都关联起来,论文就以Java应用为例子,描述了如何在代码中实现这些日志的关联。下面是Pinpoint实践章节的一些关键点汇总:
需要为每一个组件生成一个component id。
对于每一个http请求生成一个唯一的request id,并且通过线程局部变量(ThreadLocal)传递下去。
对于请求内新起来的线程,需要修改线程创建类,把request id继续传递下去。
对于请求内产生的rpc调用,需要修改请求端代码,把request id信息带入header,并在接收端解析这个header注入到线程本地变量。
每次调用到一个组件(component),就使用 (request id,component id) 组合记录一个Trace Log。
对java应用而言,这几个点技术实践简单,操作性高,为现今链路追踪系统实现链路串联,链路传播(Propegation)提供了基本思路。
这篇论文发表时间是2002年,那个时候java版本是1.4,已经具备了线程本地变量(ThreadLocal)的能力,在线程中携带信息是比较容易做到的。但又因为在那个时代切面编程还不是很普及(Spring出现在2003年,javaagent是在java 1.5才有的能力,发布于2004年),所以这样的方法并不能够被广泛应用。如果反过来想,可能正是因为这些编程需求的出现,促使着java切面编程领域的技术进步。
四、重新构建调用链路
《X-Trace: A Pervasive Network Tracing Framework》这篇论文主要研究对象是分布式集群里面的网络链路。X-Trace论文延续并扩展了Pinpoint论文的思路,提了能够重新构建完整调用链路的框架和模型。为了达到目的,文中定义了三个设计原则:
在调用链路内携带元数据(在调用链路传递的数据也称之为带内数据,in-bound data)
上报的链路信息不留存在调用链路内,收集链路信息的机制需要与应用本身正交(注:不在调用链路里面留存的链路数据,也称之为带外数据,out-of-bound data)
注入元数据的实体应该与收集报告的实体解偶。
前两个原则是沿用至今的设计原则。第三个原则则是对Poinpont思路的扩展,链路传递从原来的request id扩展了更多的元素,其中TaskID,ParentID,OpID就是trace id,parent id,span id的前身。span这个单词也在X-Trace论文的Abstract里面出现,也许是Dapper作者向X-Trace论文作者们的一种致敬。
下面再看看X-Trace对元数据的内容定义:
Flags
一个bit数组,用于标记TreeInfo、Destination、Options是否使用。
TaskID
全局唯一的id,用于标识唯一的调用链。
TreeInfo
ParentID-父节点id,调用链内唯一。
OpID-当前操作id,调用链内唯一。
EdgeType-NEXT表示兄弟关系,DOWN表示父子关系。
Destination
用于指定上报地址。
Options
预留字段,用于扩展。
除了对元数据的定义,论文还定义了两个链路传播的操作,分别是pushDown()与pushNext()。pushDown()表示拷贝元数据到下一层级,pushNext()则表示从当前节点传播元数据到下一个节点。
图5 pushDown()与pushNext()操作在调用链路中的执行的位置
在X-Trace上报链路数据的结构设计中,遵循了第2个设计原则。如图6所示,X-Trace为应用提供了一个轻量的客户端包,使得应用端可以转发链路数据到一个本地的守护进程。而本地的守护进程则是开放一个UDP协议端口,接收客户端包发过来的数据,并放入到一个队列里面。队列的另外一边则根据链路数据的具体具体配置信息,发送到对应的地方去,也许是一个数据库,也许是一个数据转发服务、数据收集服务或者是数据聚合服务。
图6
X-Trace上报链路数据的架构设计,对现在市面上的链路追踪实现有着不小的影响。对照Zipkin的collector以及Jeager的jaeger-agent,多少能够看到X-Trace的影子。
X-Trace的三个设计原则、带内带外数据的定义、元数据传播操作定义、链路数据上报架构等,都是现今链路追踪系统有所借鉴的内容。对照Zipkin的collector以及Jeager的jaeger-agent,就多少能够看到X-Trace链路数据上报架构的影子。
五、大规模商用实践——Dapper
《Dapper,a Large-Scale Distributed Systems Tracing Infrastructure》论文中,Dapper是谷歌内部用于给开发者们提供复杂分布式系统行为信息的系统。Dapper论文则是介绍谷歌对这个分布式链路追踪基础设施设计和实践的经验。Dapper论文发布于2010年,根据论文的表述,Dapper系统已经在谷歌内部有两年的实践经验了。
Dapper系统的主要目的是给开发者提供提供复杂分布式系统行为信息。文中分析为了实现这样的系统,需要解决什么样的问题。并根据这些问题提出了两个基本的设计需求:大范围部署和持续性的监控。针对着两个基本设计要求,提出了三个具体的设计目标:
低开销(Low overhead):链路追踪系统需要保证对在线服务的的性能影响做到忽略不计的程度。即使是很小的监控消耗也会对一些高度优化过的服务有可觉察的影响,甚至迫使部署团队关闭追踪系统。
应用级透明化(Application-level transparecy):开发者不应该感知到链路追踪设施。如果链路追踪系统需要依赖应用级开发者协助才能够工作,那么这个链路追踪设施会变得非常最弱,而且经常会因为 bugs 或者疏忽导致无法正常工作。这违反了大范围部署的设计需求。
可伸缩性(Scalability):链路追踪系统需要能够满足Google未来几年的服务和集群的规模。
虽然Dapper的设计概念与Pinpoint、Magpie、X-Trace有许多是想通的,但是Dapper也有自己的一些独到的设计。其中一点就是为了达到低开销的设计目标,Dapper对请求链路进行了采样收集。根据Dapper在谷歌的实践经验,对于许多常用的场景,即使对1/1000的请求进行采样收集,也能够得到足够的信息。
另外一个独到的特点是他们实现非常高的应用透明度。这个得益于Google应用集群部署有比较高的同质化,他们可以把链路追踪设施实现代码限制在软件的底层而不需要在应用里面添加而外的注解信息。举个例子,集群内应用如果使用相同的http库、消息通知库、线程池工厂和RPC库,那么就可以把链路追踪设施限制在这些代码模块里面。
六、如何定义链路信息的?
文中首先举了一个简单的调用链例子,如图7,作者认为对一个请求做分布式追踪需要收集消息的识别码以及消息对应的事件与时间。如果只考虑RPC的情况,调用链路可以理解为是RPCs嵌套树。当然,谷歌内部的数据模型也不局限于RPCs调用。
图7
图8阐述了Dapper追踪树的结构,树的节点为基本单元,称之为span。边线为父子span之间的连接。一个span就是简单带有起止时间戳、RPC耗时或者应用相关的注解信息。为了重新构建Dapper追踪树,span还需要包含以下信息:
span name: 易于阅读的名字,如图8中的Frontend.Request
span id: 一个64bit的唯一标识符
parent id: 父 span id
图9是一个RPC span的详细信息。值得一提的是,一个相同的span可能包含多个主机的信息。实际上,每一个RPC span都包含了客户端和服务端处理的注释。由于客户端的时间戳和服务端的时间戳来自不同的主机,所以需要异常关注这些时间的异常情况。图9是一个span的详细信息:
七、如何实现应用级透明的?
Dapper通过对一些通用包添加测量点,对应用开发者在零干扰的情况下实现了分布式链路追踪,主要有以下实践:
当一个线程在处理链路追踪路径上时,Dapper会把追踪上下文关联到线程本地存储。追踪上下文是一个小巧且容易复制的span信息容易。
如果计算过程是延迟的或者一步的,大多谷歌开发者会使用通用控制流库来构造回调函数,并使用线程池线程池或者其他执行器来调度。这样Dapper就可以保证所有的回调函数会在创建的时候存储追踪上下文,在回调函数被执行的时候追踪上下文关联到正确线程里面。
Google几乎所有的线程内通信都是建立在一个RPC框架构建的,包括C++和Java的实现。框架添加上了测量,用于定义所有RPC调用相关 span。在被跟踪的RPC、span和trace的id会从客户端传递到服务端。在Google这个是非常必要的测量点。
八、结语
Dapper论文给出了易于阅读和有助于问题定位的数据模型设计、应用级透明的测量实践以及低开销的设计方案,为链路追踪在工业级应用的使用清除了不少障碍,也激发了不少开发者的灵感。自从《Google Dapper》论文出来之后,不少开发者受到论文的启发,开发出了各式各样的链路追踪,2012年推特开源Zipkin、Naver开源Pinpoint,2015年吴晟开源Skywalking、Uber开源Jaeger等。从此链路追踪进入了百家争鸣的时代。
快来留言区写下本文读后感吧,分享你学习链路追踪技术的收获与切身感悟~
推荐阅读
如有侵权请联系:admin#unsafe.sh