
关于何为Proguard,可以参考GuardSquare官网其优化业务及Wikipedia相关条目.
Proguard:https://www.guardsquare.com/proguard
Wikipedia:https://en.wikipedia.org/wiki/ProGuard
2017年6月,Richard Baumann发表了标题为"Anti-ProGuard: Towards Automated Deobfuscation of Android Apps"(DOI:10.1145/3099012.3099020)的论文,其旨在利用SimHash算法实现对Apk的自动化反混淆.关于何为SimHash,简要来讲可以理解为可用之计算两个文本片段相似度的算法,此处不再进行具体阐述,可以参考Google在2007年发表的论文"Detecting Near-Duplicates for Web Crawling"(DOI:10.1145/1242572.1242592).

论文第二部分中,其强调Proguard对Apk进行Obfuscating的过程是多个Transformation的集合,论文设欲混淆工程为P,而P可看作同时包含多个对象的对象集合,对象集合中包含的对象与未混淆之工程中的类,方法,成员一 一存在映射关系,作者统一称这些对象为S.即P={S1,S2,S3...}
经过Proguard混淆后的工程设之为P',而Proguard的混淆过程可看作一个能够传入任意量的Transformation函数T(x),即P'={T(S1),T(S2),T(S3)...}.可见论文强调整个混淆过程为对整个未混淆工程中各个元素进行转换的总和(事实上也确实如此),而该思想在接下来的分析中也会多次得到体现.
而论文中的第三部分正式进入到自动化反混淆的实现部分,但由于论文中阐述的实现思路略去了很多细节,故下文不以论文进行分析,而Richard Baumann已经将自动化方案落地,在其Github账户ohaz下即可找到对应的POC项目(论文中并未给出其实现的项目地址,而该项目的首次commit时间最早为2016年,即早于论文发布时间).接下来以该项目具体分析自动化反混淆的实现思路.
https://github.com/ohaz/antiproguard
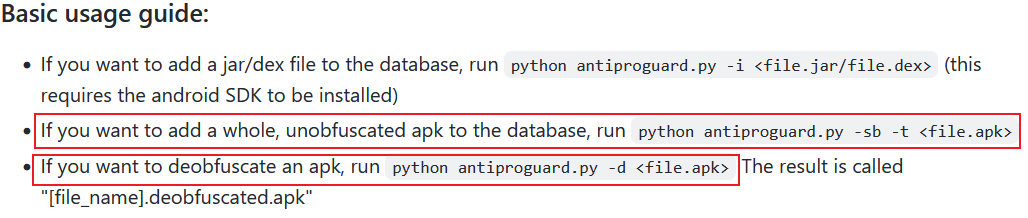
作者在其项目README文件上简述了工具的基本使用,需要引起注意的是其工具的--sb -t参数与-d参数,其前者用于指定一个未被混淆的Apk,并将未混淆Apk之包,类,方法名及其对应的方法实体逐一抽离提取,存入数据库,后者为反混淆的进行指定一个欲反混淆的Apk.
由于篇幅限制,下文仅对项目最核心的算法部分进行分析,并在分析前假设一个前提:数据库中已经填充了足够多的未混淆Apk.
项目中antiproguard.py申明了一个关键方法compare,该方法用于将传入的欲分析方法实体(被混淆)与数据库中储存的各个方法实体(未混淆)分别进行相似度对比,并依据相似度对比结果判断是否生成一个hint,该生成的hint将作为辅助分析其他被混淆方法实体的依据.

可见在compare方法内,程序分别对被混淆方法实体分别生成了三个不同的SimHash值,而经过后续验证,这三个SimHash的产生均与方法实体所对应的操作码串有高度关联,则此三个SimHash值的关系可以下图进行表达.

由上图不难得知这三个SimHash值与被混淆方法实体的关联强度有关,并按照关联强度以由大到小的顺序排列.
接着该三值分别与数据库中的未混淆方法实体对应产生的此三个SimHash值以论文中提到的如下方式分别进行一次计算:
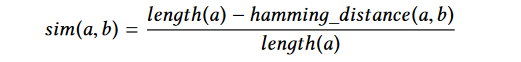
SimHash结合汉明距离,该计算方式得出的结果可抽象理解为两个方法实体的相似程度,接着程序判断计算出的相似程度是否大于90%,若超过该值,则判断该被混淆方法实体与正在与之进行对比的未混淆方法实体高度相似,此时即可为下一次compare的调用产生一个hint,根据该hint以加快识别其他方法实体相似程度的速度,此处不再对hint更进一步分析.
而最终程序将对所有经过compare方法确定的与数据库中未混淆的方法实体产生对应关系的被混淆的方法实体进行批量重命名,将其方法名'还原'为数据库中对应的未混淆方法实体的对应方法名,简而言之,compare方法负责确定被混淆方法与数据库中的那个未混淆方法具有强相关的关系.
如果已经理解了compare方法,不难看出compare方法与反混淆之精细程度有着直接关系,同时也不难得出该反混淆方案的本质.既已分析过关键方法,剩下的分析流程我仅以一图概之.
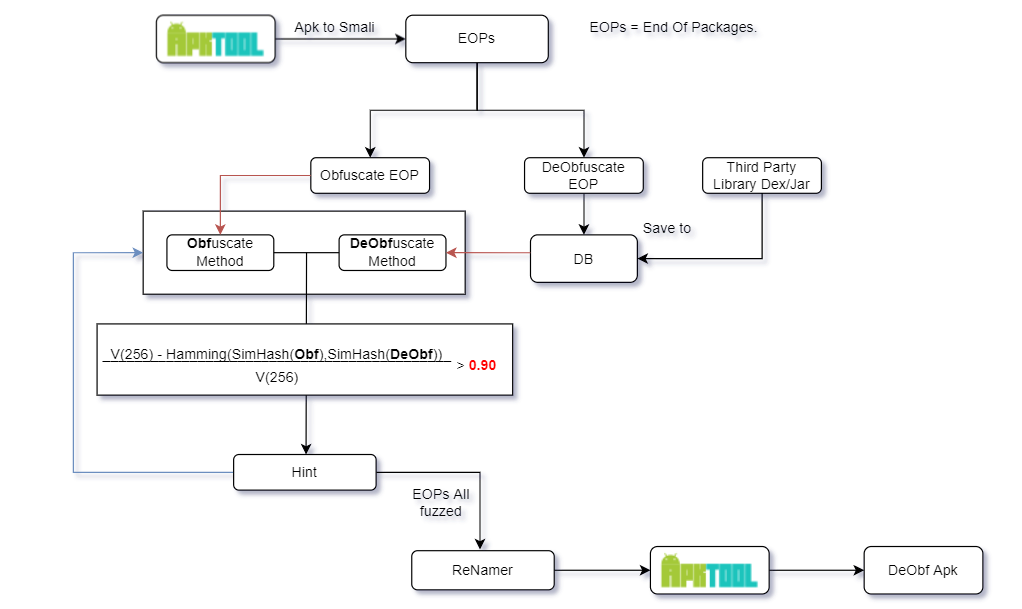
虽方案可行,但仍有局限之处,且看该论文的第四部分.

可见其选择的被测试对象均为F-Droid上开放源代码的项目,且这些项目至少使用了一个或多个开源的第三方库,这些开源第三方库将在正式测试前被导入至数据库中,以启用Proguard优化的情况下编译项目,以反混淆工具提供的方案处理之,虽然最终该反混淆方案正确还原的包超过了50%,但该方案依然在很大程度上无法胜任真正的逆向工程实战.
- 其一,回顾上文对关键方法
compare的分析,不难发现一个需求与方案实现上的冲突,即逆向工程的本质是分析与剥离被分析对象最有价值的核心代码,而根据compare的实现可知其对方法实体的分析基于数据库中数据量的多少,而能够输入数据库的数据也仅限于第三方的开源支持库(你总不能输入一些能够还原未开源代码的数据吧,这形成了悖论).

- 其二,论文第一部分明确指出,其所提出的基于相似性算法的混淆代码还原方案基于数据库中的已知代码,而如第一点所言,能输入数据库的代码主要来源于第三方的开源支持库,故该论文提出的所谓通用性方案仅能对本就开源但被混淆的部分进行还原.
基于以上两点假设一个理想情况,方案能够还原所有被混淆的第三方开源库代码,但需要明确的是,逆向工程的主要对象仍是针对软件的业务代码,而市面上投放的软件其业务代码量均十分庞大(想象一下如今用户能够从已知渠道下载的软件,其臃肿程度导致的代码量可见一斑),即使能还原所有第三方开源库代码,对逆向工程的帮助也是微乎其微.
不论是尝试'还原'被混淆为短字节的方法名还是以其他方式处理被Proguard混淆的Apk工程,不难发现这些工作的本质都是尝试辅助逆向工程人员'理解'被混淆方法实体,排除无意义短字节的干扰,以减少逆向工程中抽离出有价值代码的时间成本.
基于该思想,我曾于21年4月份编写并开源过一个项目,该项目的主旨是通过分析被混淆的成员与成员,方法,类之间的关系,让逆向工程人员快速判断被混淆成员是否具有被分析价值,但由于当时该项目不与任何现有工具联动,且分析对象仅针对成员,职能单一,在逆向工程中发挥的作用不大,故在今年(22年)5月对部分代码重构,拓展了项目职能,目前可以与著名逆向工程工具JADX进行联动,且分析对象由单一的成员拓展至方法,可通过分析欲分析方法中的参数在被标记为污点的情况下的向下传播方向,即DataFlow分析.
https://github.com/MG1937/AntiProguard-KRSFinder

而该项目的实现本质无疑是分析整个Apk工程的Dalvik操作码,为操作码分配相应的句柄以具体处理操作码的操作对象,并依据处理结果进一步分析Apk内各个类的成员与方法,生成对应的分析报告用以联动JADX.(关于Dalvik操作码,可以参考Gabor Paller于2009年提供的Dalvik Opcodes).
像Dalvik虚拟机一样思考
分析Apk无不分析其Dex,分析Dex无不Dump其IR,得其IR,何如?
正如前文所述,该项目旨在通过分析成员间关系与DataFlow以辅助逆向工程,然则不论如何分析,深入到Dex文件其操作码总是必要的.虽从Dex中获取Dalvik操作码的方法有千百种,但论如何处理操作码及其处理思想,固然是要引Google之鉴的.然则自Android5.0开始,Google就弃用Dalvik转而以ART虚拟机处理Dex,但ART绝大情况下使用AOT技术,仅于技术需求而言,该项目对操作码的处理思想必然要取JIT之鉴,故该部分将分析Dalvik虚拟机处理字节码的部分实现,进以指导项目实现.
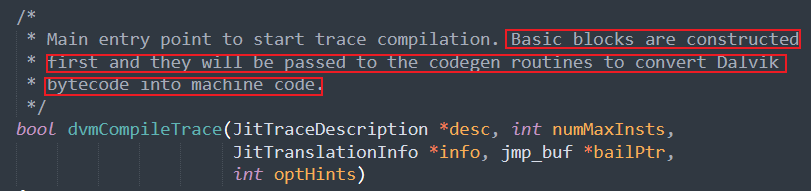
以Android-4.0.1_r1分支下的Dalvik虚拟机源码为例,Dex实例将流入Frontend.cpp文件下dvmCompileTrace函数,该函数正是将Dalvik字节码转换为机器码的入口函数.
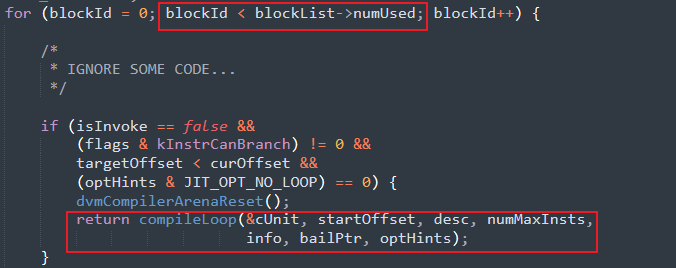
该函数不断遍历包含字节码的基本块,最终将携带Dalvik字节指令的cUnit成员引用传入compileLoop函数下,而compileLoop函数最终将引用传入CodegenDriver.cpp文件下的关键函数 dvmCompilerMIR2LIR,顾名思义,此函数将Dalvik字节指令处理为LIR,最终由其他方法处理LIR为机器码.
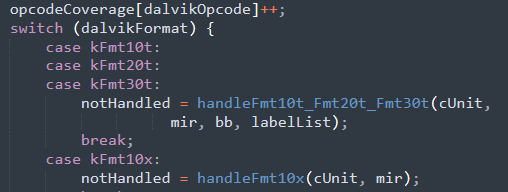
dvmCompilerMIR2LIR函数下cUnit成员引用中携带的Dalvik字节码被传入dexGetFormatFromOpcode函数下处理为dalvikFormat成员,最终该成员被传入一个巨大的switch-case块中进行处理,该switch-case块根据dalvikFormat成员为cUnit成员分配对应的处理句柄(handle)以具体处理其携带的Dalvik字节码即其操作对象(即寄存器).
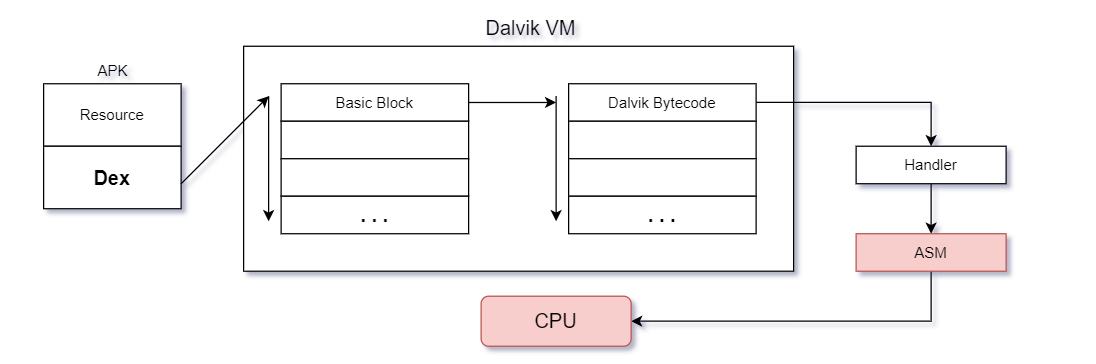
至此,Android4.0 Dalvik虚拟机处理字节码的大致流程已经分析完毕,如上图流程图所示,该流程及其Dalvik字节码处理思想将被运用到接下来的项目结构中.
项目实现
项目已经开源,可至AntiProguard-KRSFinder下查看项目具体代码.
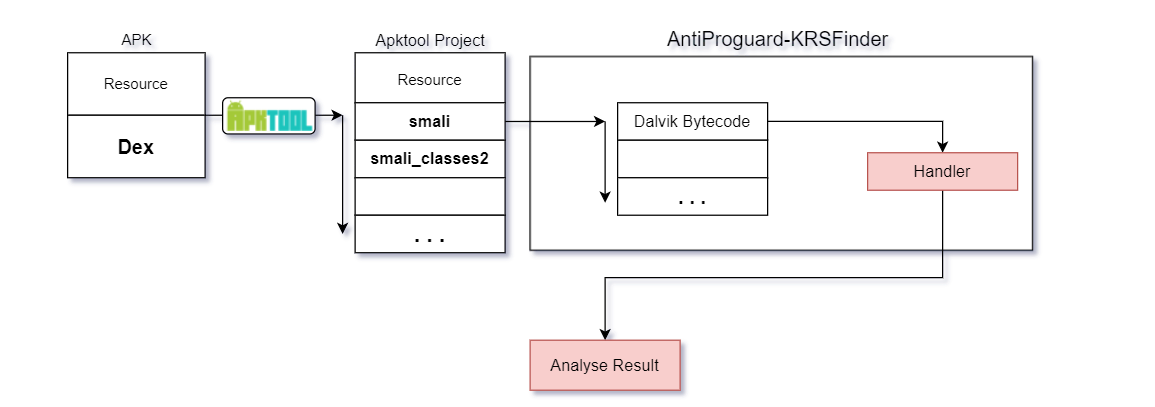
基于前文对Dalvik虚拟机处理字节码的流程分析,基于Dalvik思想绘制如上流程图,该图所示流程在项目正式开始前被作为理想流程框架用以指导项目进行,并且在已经完成的项目中其对字节码的大致处理流程也接近该理想流程框架.

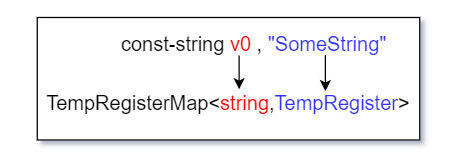
由Dalvik虚拟机源码下docs文件夹中文档的部分描述可知Dalvik虚拟机是基于寄存器的.故项目也需要一个组件用以储存寄存器,该组件即为项目中TempRegisterMap.cs文件下的TempRegisterMap类.而该组件本质上是一个Dictionary对象,该组件其键为Dalvik操作码具体操作的寄存器其名(即p0,v0...),其值为TempRegister对象,该对象即代表一个具体的寄存器,此寄存器目前仅需要储存字符串与方法.下图为该组件大致结构.
下面部分为项目对单个Dalvik字节码处理部分,该部分模仿了Dalvik虚拟机处理字节码的模式.
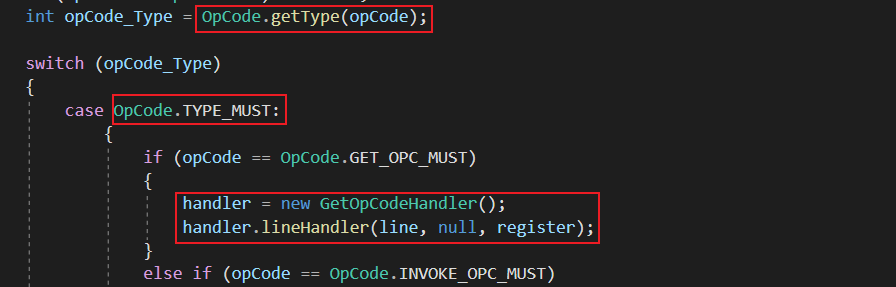
上图为项目下MethodCodeAnalyseModule.cs文件中MethodCodeAnalyseModule类的methodAnalyse 函数,该函数为项目处理操作码的正式入口,可以看到该部分我效仿Dalvik虚拟机处理单个字节码的流程模式,为即将处理的操作码分类,并为之分配处理句柄以具体解析操作码及其携带的寄存器,值得一提的是该函数的实现并不完全与Dalvik虚拟机处理操作码的形式相同,在正式为操作码分配处理句柄前,我将操作码的处理优先级以 MUST,CHECK,PASS 划分,被赋予MUST优先级的操作码将被优先分配处理句柄,赋予CHECK优先级的操作码将在检查其具体操作的寄存器是否有必要处理后再为操作码分配处理句柄,赋予PASS优先级的操作码将不进行任何解析,以此略去部分不必要解析的操作码,以加快整个流程的处理速度.
在正式进入下个部分前,有必要阐述清楚函数中方法区块(以下称为块)的含义.
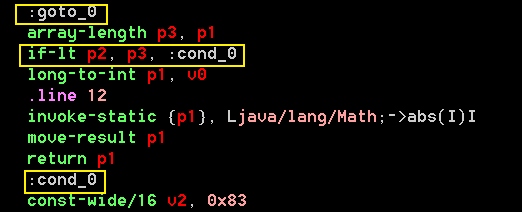
Dex中以MIR形式储存的函数不仅以多个字节码组成的串形式保存,单个函数也可被分为多个块,即以多个块组成一个函数,欲简单理解块,可以ASM中的JMP指令为参考,JMP指令可以跳跃到内存中的任意地址,而在Dalvik中则以块为跳跃对象,即在Dalvik中以块为基本单位组成执行流程.以市面上常见的工具抽离Dex其操作码串,输出的结果中大多以高级语言中Label的形式表示函数中的块,如下图为带有多个块的函数片段.
下面部分为项目对单个函数的处理部分.
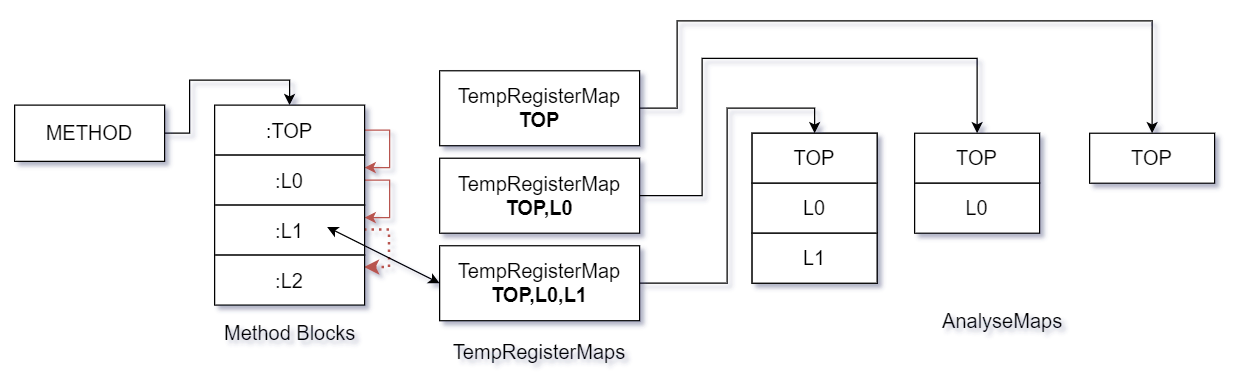
先假设项目即将对一个函数进行处理,且该函数被分为数量未知的多个块,而上图所示流程即为项目在该情况下的大致处理流程,假设一个理想情况,此时块与块之间没有任何指令使得程序跨块跳跃,即执行流程从块顶部向下执行直到方法结束,那么项目将在每个块执行结束时,立刻截取当前块的寄存器集(即TempRegisterMap组件)快照,并且记录当前的执行路线,以寄存器集快照为引索保存每次执行路线,那么在该执行流程下,寄存器集将以如下图情况保存.
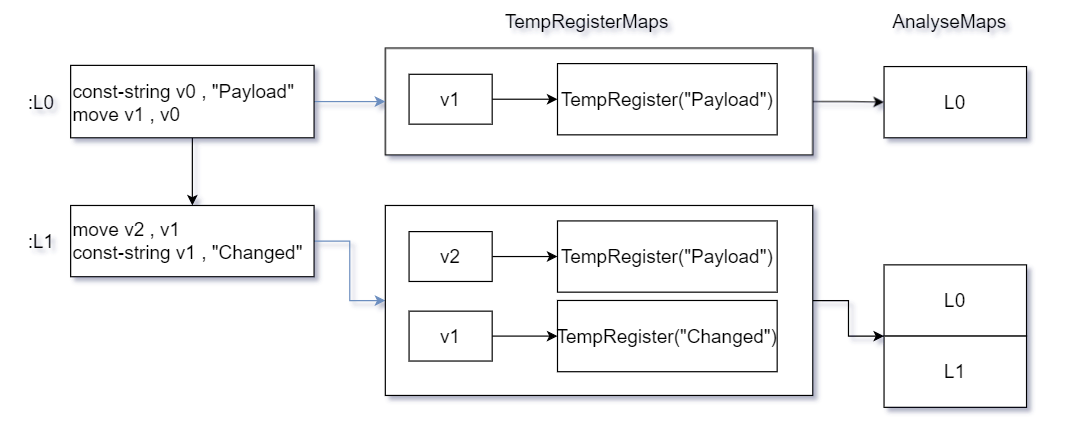
那么此时假设块与块之间出现了一个或多个流程控制指令(如if,goto).
- 若流程控制指令为
goto指令,项目将标记其操作对象为强行跳转目标,并继续向下执行,但不具体解析非强行跳转目标的块,直到目标块被找到才具体对块中操作码进行解析. - 若为
if类指令,项目将仅对其操作对象进行标记,而不令项目强行寻找目标块,正常向下执行并解析块.
以如上两种流程控制方法尽可能覆盖到大多数由流程控制指令导致的未知数量的解析路线.
假设块与块之间出现了数量未知的goto指令,此时处理流程将为下图所示.
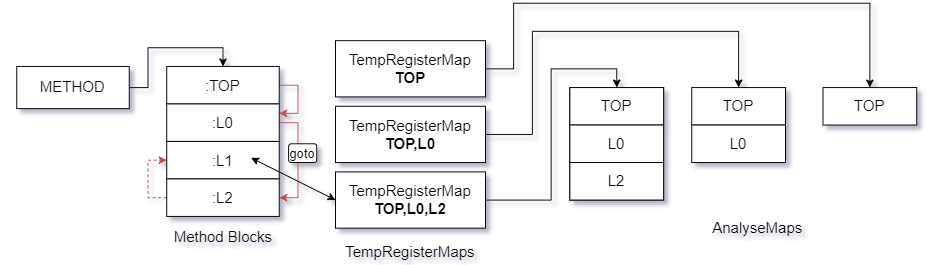
从流程上来看似乎处理过程没有太大变化,但此时构造一个在Dalvik执行流程上能够影响寄存器内容的函数片段,此时且看下图处理结果.
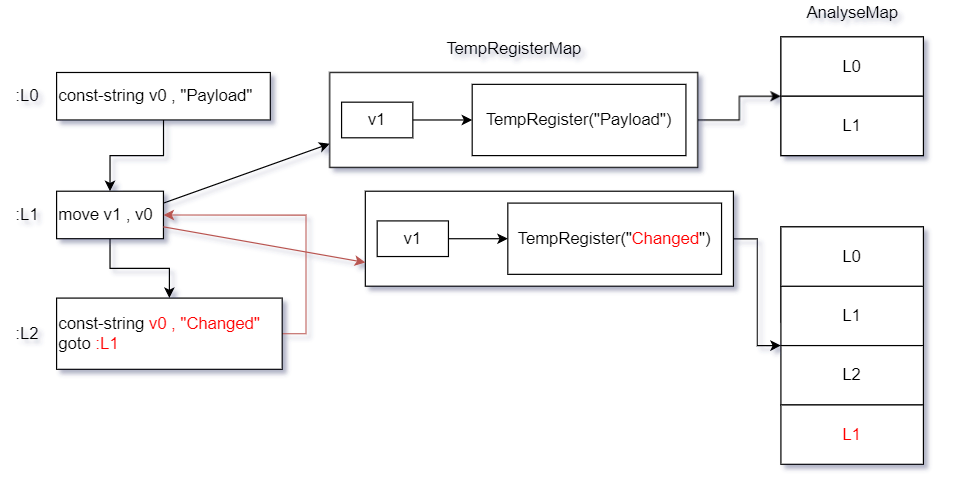
项目对流程的控制及寄存器集快照保存的作用就在此体现,从上图给出的函数片段可知块L1中的v1寄存器为执行流程所改变,若不保存寄存器集快照,就不能够完全记录寄存器的前后变化.
上文即为项目对单个函数的大致处理流程,该部分也是项目最核心的部分,不论是成员关系分析还是DataFlow分析,其结果的精确度都依赖于此,更多细节不再在此文写出,至此,本文完结.
如有侵权请联系:admin#unsafe.sh