
Loading...


There is a famous quote attributed to a Netscape engineer: “There are only two difficult problems in computer science: cache invalidation and naming things.” While naming things does oddly take up an inordinate amount of time, cache invalidation shouldn’t.
In the past we’ve written about Cloudflare’s incredibly fast response times, whether content is cached on our global network or not. If content is cached, it can be served from a Cloudflare cache server, which are distributed across the globe and are generally a lot closer in physical proximity to the visitor. This saves the visitor’s request from needing to go all the way back to an origin server for a response. But what happens when a webmaster updates something on their origin and would like these caches to be updated as well? This is where cache “purging” (also known as “invalidation”) comes in.
Customers thinking about setting up a CDN and caching infrastructure consider questions like:
- How do different caching invalidation/purge mechanisms compare?
- How many times a day/hour/minute do I expect to purge content?
- How quickly can the cache be purged when needed?
This blog will discuss why invalidating cached assets is hard, what Cloudflare has done to make it easy (because we care about your experience as a developer), and the engineering work we’re putting in this year to make the performance and scalability of our purge services the best in the industry.
What makes purging difficult also makes it useful
(i) Scale
The first thing that complicates cache invalidation is doing it at scale. With data centers in over 270 cities around the globe, our most popular users’ assets can be replicated at every corner of our network. This also means that a purge request needs to be distributed to all data centers where that content is cached. When a data center receives a purge request, it needs to locate the cached content to ensure that subsequent visitor requests for that content are not served stale/outdated data. Requests for the purged content should be forwarded to the origin for a fresh copy, which is then re-cached on its way back to the user.
This process repeats for every data center in Cloudflare’s fleet. And due to Cloudflare’s massive network, maintaining this consistency when certain data centers may be unreachable or go offline, is what makes purging at scale difficult.
Making sure that every data center gets the purge command and remains up-to-date with its content logs is only part of the problem. Getting the purge request to data centers quickly so that content is updated uniformly is the next reason why cache invalidation is hard.
(ii) Speed
When purging an asset, race conditions abound. Requests for an asset can happen at any time, and may not follow a pattern of predictability. Content can also change unpredictably. Therefore, when content changes and a purge request is sent, it must be distributed across the globe quickly. If purging an individual asset, say an image, takes too long, some visitors will be served the new version, while others are served outdated content. This data inconsistency degrades user experience, and can lead to confusion as to which version is the “right” version. Websites can sometimes even break in their entirety due to this purge latency (e.g. by upgrading versions of a non-backwards compatible JavaScript library).
Purging at speed is also difficult when combined with Cloudflare’s massive global footprint. For example, if a purge request is traveling at the speed of light between Tokyo and Cape Town (both cities where Cloudflare has data centers), just the transit alone (no authorization of the purge request or execution) would take over 180ms on average based on submarine cable placement. Purging a smaller network footprint may reduce these speed concerns while making purge times appear faster, but does so at the expense of worse performance for customers who want to make sure that their cached content is fast for everyone.
(iii) Scope
The final thing that makes purge difficult is making sure that only the unneeded web assets are invalidated. Maintaining a cache is important for egress cost savings and response speed. Webmasters’ origins could be knocked over by a thundering herd of requests, if they choose to purge all content needlessly. It’s a delicate balance of purging just enough: too much can result in both monetary and downtime costs, and too little will result in visitors receiving outdated content.
At Cloudflare, what to invalidate in a data center is often dictated by the type of purge. Purge everything, as you could probably guess, purges all cached content associated with a website. Purge by prefix purges content based on a URL prefix. Purge by hostname can invalidate content based on a hostname. Purge by URL or single file purge focuses on purging specified URLs. Finally, Purge by tag purges assets that are marked with Cache-Tag headers. These markers offer webmasters flexibility in grouping assets together. When a purge request for a tag comes into a data center, all assets marked with that tag will be invalidated.
With that overview in mind, the remainder of this blog will focus on putting each element of invalidation together to benchmark the performance of Cloudflare’s purge pipeline and provide context for what performance means in the real-world. We’ll be reviewing how fast Cloudflare can invalidate cached content across the world. This will provide a baseline analysis for how quick our purge systems are presently, which we will use to show how much we will improve by the time we launch our new purge system later this year.
How does purge work currently?
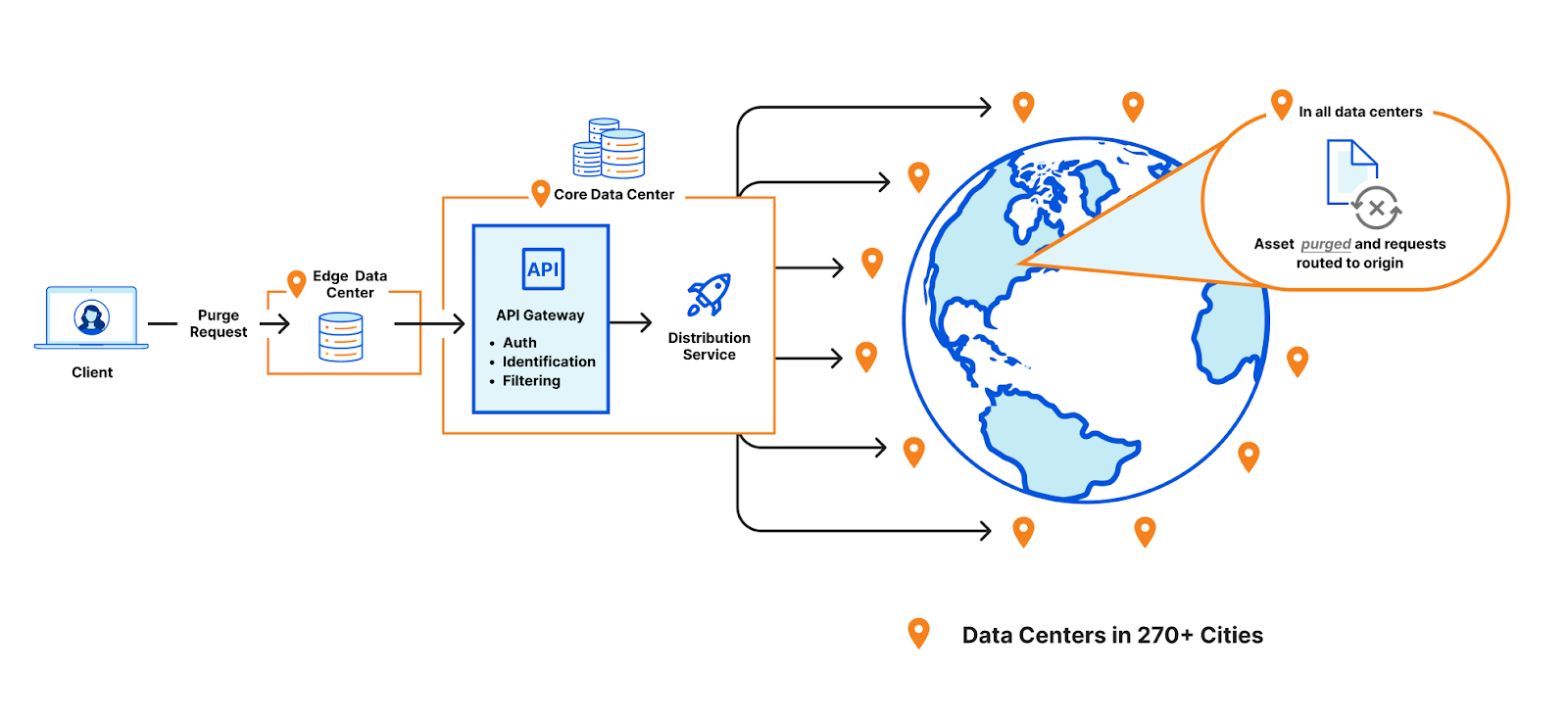
In general, purge takes the following route through Cloudflare’s data centers.
- A purge request is initiated via the API or UI. This request specifies how our data centers should identify the assets to be purged. This can be accomplished via cache-tag header(s), URL(s), entire hostnames, and much more.
- The request is received by any Cloudflare data center and is identified to be a purge request. It is then routed to a Cloudflare core data center (a set of a few data centers responsible for network management activities).
- When a core data center receives it, the request is processed by a number of internal services that (for example) make sure the request is being sent from an account with the appropriate authorization to purge the asset. Following this, the request gets fanned out globally to all Cloudflare data centers using our distribution service.
- When received by a data center, the purge request is processed and all assets with the matching identification criteria are either located and removed, or marked as stale. These stale assets are not served in response to requests and are instead re-pulled from the origin.
- After being pulled from the origin, the response is written to cache again, replacing the purged version.
Now let’s look at this process in practice. Below we describe Cloudflare’s purge benchmarking that uses real-world performance data from our purge pipeline.
Benchmarking purge performance design
In order to understand how performant Cloudflare’s purge system is, we measured the time it took from sending the purge request to the moment that the purge is complete and the asset is no longer served from cache.
In general, the process of measuring purge speeds involves: (i) ensuring that a particular piece of content is cached, (ii) sending the command to invalidate the cache, (iii) simultaneously checking our internal system logs for how the purge request is routed through our infrastructure, and (iv) measuring when the asset is removed from cache (first miss).
This process measures how quickly cache is invalidated from the perspective of an average user.
- Clock starts
As noted above, in this experiment we’re using sampled RUM data from our purge systems. The goal of this experiment is to benchmark current data for how long it can take to purge an asset on Cloudflare across different regions. Once the asset was cached in a region on Cloudflare, we identify when a purge request is received for that asset. At that same instant, the clock started for this experiment. We include in this time any retrys that we needed to make (due to data centers missing the initial purge request) to ensure that the purge was done consistently across our network. The clock continues as the request transits our purge pipeline (data center > core > fanout > purge from all data centers). - Clock stops
What caused the clock to stop was the purged asset being removed from cache, meaning that the data center is no longer serving the asset from cache to visitor’s requests. Our internal logging measures the precise moment that the cache content has been removed or expired and from that data we were able to determine the following benchmarks for our purge types in various regions.
Results
We’ve divided our benchmarks in two ways: by purge type and by region.
We singled out Purge by URL because it identifies a single target asset to be purged. While that asset can be stored in multiple locations, the amount of data to be purged is strictly defined.
We’ve combined all other types of purge (everything, tag, prefix, hostname) together because the amount of data to be removed is highly variable. Purging a whole website or by assets identified with cache tags could mean we need to find and remove a multitude of content from many different data centers in our network.
Secondly, we have segmented our benchmark measurements by regions and specifically we confined the benchmarks to specific data center servers in the region because we were concerned about clock skews between different data centers. This is the reason why we limited the test to the same cache servers so that even if there was skew, they’d all be skewed in the same way.
We took the latency from the representative data centers in each of the following regions and the global latency. Data centers were not evenly distributed in each region, but in total represent about 90 different cities around the world:
- Africa
- Asia Pacific Region (APAC)
- Eastern Europe (EEUR)
- Eastern North America (ENAM)
- Oceania
- South America (SA)
- Western Europe (WEUR)
- Western North America (WNAM)
The global latency numbers represent the purge data from all Cloudflare data centers in over 270 cities globally. In the results below, global latency numbers may be larger than the regional numbers because it represents all of our data centers instead of only a regional portion so outliers and retries might have an outsized effect.
Below are the results for how quickly our current purge pipeline was able to invalidate content by purge type and region. All times are represented in seconds and divided into P50, P75, and P99 quantiles. Meaning for “P50” that 50% of the purges were at the indicated latency or faster.
Purge By URL
| P50 | P75 | P99 | |
|---|---|---|---|
| AFRICA | 0.95s | 1.94s | 6.42s |
| APAC | 0.91s | 1.87s | 6.34s |
| EEUR | 0.84s | 1.66s | 6.30s |
| ENAM | 0.85s | 1.71s | 6.27s |
| OCEANIA | 0.95s | 1.96s | 6.40s |
| SA | 0.91s | 1.86s | 6.33s |
| WEUR | 0.84s | 1.68s | 6.30s |
| WNAM | 0.87s | 1.74s | 6.25s |
| GLOBAL | 1.31s | 1.80s | 6.35s |
Purge Everything, by Tag, by Prefix, by Hostname
| P50 | P75 | P99 | |
|---|---|---|---|
| AFRICA | 1.42s | 1.93s | 4.24s |
| APAC | 1.30s | 2.00s | 5.11s |
| EEUR | 1.24s | 1.77s | 4.07s |
| ENAM | 1.08s | 1.62s | 3.92s |
| OCEANIA | 1.16s | 1.70s | 4.01s |
| SA | 1.25s | 1.79s | 4.106s |
| WEUR | 1.19s | 1.73s | 4.04s |
| WNAM | 0.9995s | 1.53s | 3.83s |
| GLOBAL | 1.57s | 2.32s | 5.97s |
A general note about these benchmarks — the data represented here was taken from over 48 hours (two days) of RUM purge latency data in May 2022. If you are interested in how quickly your content can be invalidated on Cloudflare, we suggest you test our platform with your website.
Those numbers are good and much faster than most of our competitors. Even in the worst case, we see the time from when you tell us to purge an item to when it is removed globally is less than seven seconds. In most cases, it’s less than a second. That’s great for most applications, but we want to be even faster. Our goal is to get cache purge to as close as theoretically possible to the speed of light limit for a network our size, which is 200ms.
Intriguingly, LEO satellite networks may be able to provide even lower global latency than fiber optics because of the straightness of the paths between satellites that use laser links. We've done calculations of latency between LEO satellites that suggest that there are situations in which going to space will be the fastest path between two points on Earth. We'll let you know if we end up using laser-space-purge.
Just as we have with network performance, we are going to relentlessly measure our cache performance as well as the cache performance of our competitors. We won’t be satisfied until we verifiably are the fastest everywhere. To do that, we’ve built a new cache purge architecture which we’re confident will make us the fastest cache purge in the industry.
Our new architecture
Through the end of 2022, we will continue this blog series incrementally showing how we will become the fastest, most-scalable purge system in the industry. We will continue to update you with how our purge system is developing and benchmark our data along the way.
Getting there will involve rearchitecting and optimizing our purge service, which hasn’t received a systematic redesign in over a decade. We’re excited to do our development in the open, and bring you along on our journey.
So what do we plan on updating?
Introducing Coreless Purge
The first version of our cache purge system was designed on top of a set of central core services including authorization, authentication, request distribution, and filtering among other features that made it a high-reliability service. These core components had ultimately become a bottleneck in terms of scale and performance as our network continues to expand globally. While most of our purge dependencies have been containerized, the message queue used was still running on bare metals, which led to increased operational overhead when our system needed to scale.
Last summer, we built a proof of concept for a completely decentralized cache invalidation system using in-house tech – Cloudflare Workers and Durable Objects. Using Durable Objects as a queuing mechanism gives us the flexibility to scale horizontally by adding more Durable Objects as needed and can reduce time to purge with quick regional fanouts of purge requests.
In the new purge system we’re ripping out the reliance on core data centers and moving all that functionality to every data center, we’re calling it coreless purge.
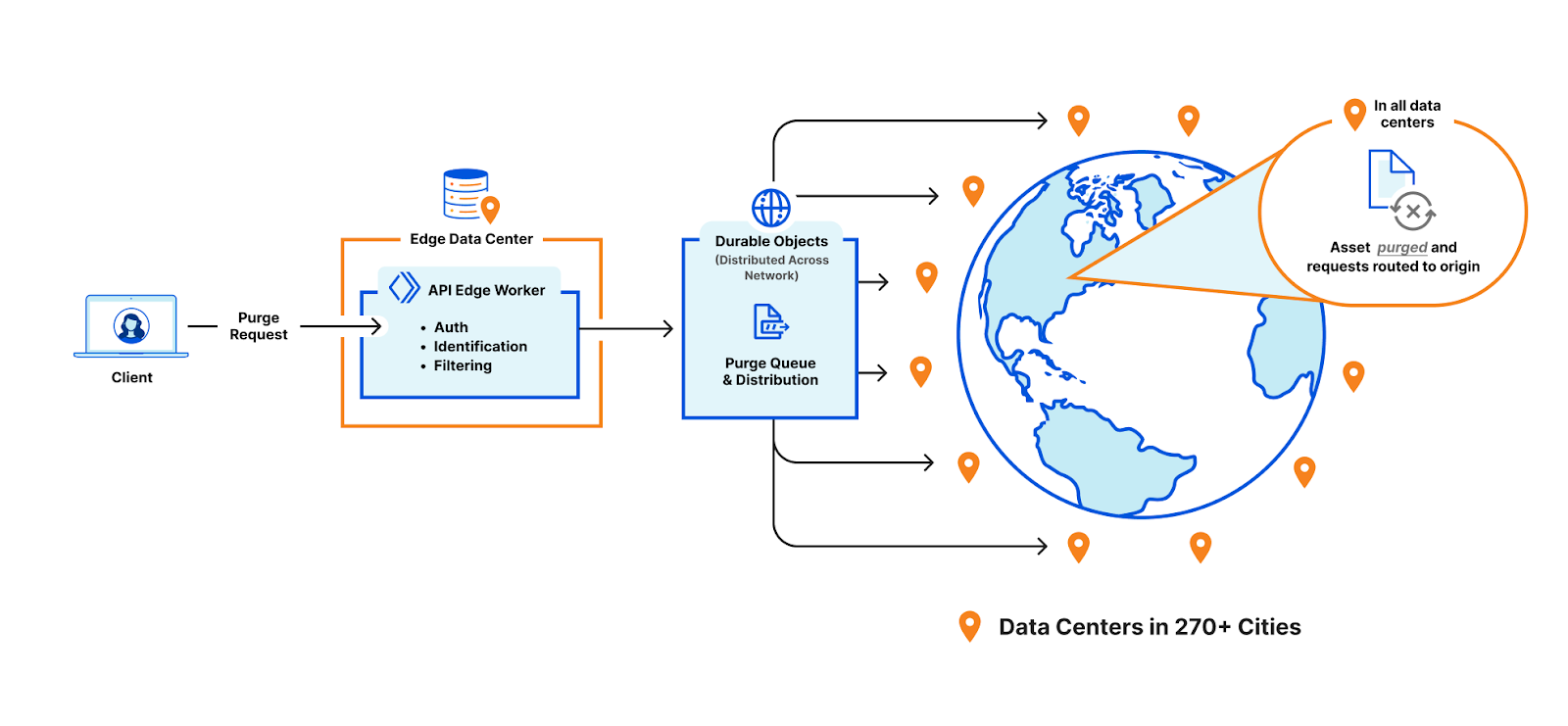
Here’s a general overview of how coreless purge will work:
- A purge request will be initiated via the API or UI. This request will specify how we should identify the assets to be purged.
- The request will be routed to the nearest Cloudflare data center where it is identified to be a purge request and be passed to a Worker that will perform several of the key functions that currently occur in the core (like authorization, filtering, etc).
- From there, the Worker will pass the purge request to a Durable Object in the data center. The Durable Object will queue all the requests and broadcast them to every data center when they are ready to be processed.
- When the Durable Object broadcasts the purge request to every data center, another Worker will pass the request to the service in the data center that will invalidate the content in cache (executes the purge).
We believe this re-architecture of our system built by stringing together multiple services from the Workers platform will help improve both the speed and scalability of the purge requests we will be able to handle.
Conclusion
We’re going to spend a lot of time building and optimizing purge because, if there’s one thing we learned here today, it's that cache invalidation is a difficult problem but those are exactly the types of problems that get us out of bed in the morning.
If you want to help us optimize our purge pipeline, we’re hiring.