
2021-09-25 03:48:35 Author: jcjc-dev.com(查看原文) 阅读量:36 收藏
24 Sep 2021
Unless you’ve been living under a rock for the past decade, I’m sure you’ve noticed the growing online trends of disinformation being pushed around. The public has been made acutely aware of propagandistic tools like fake news, social media bots, troll farms, information leaks, etc.
Mainstream media sources have openly discussed the inner workings of highly capable manipulation actors like Cambridge Analytica. Stories that taught us propagandistic operations have been taken to a level that would startle Orwell himself: Automated psychological profiling of individuals at a large scale, followed by highly targeted delivery of disinformation, packaged in whichever way is most likely to influence each psychological profile.
The modern technological landscape has been largely architected to help companies influence consumers into buying one thing or another. That manipulation infrastructure has proven amazingly useful for political and propagandistic purposes, laying the road for a very frightening period: The era of large scale targeted manipulation.
These posts aim to present the technological and sociological landscape we share with these influential forces, ponder about their capabilities and methodologies, try to understand what to expect from them, and discuss how to fend off malicious influences.
Personal note: If you’ve read anything I’ve published before, you may have noticed I very rarely engage in public discussions regarding politics or social movements. That’s for a series of personal reasons; mostly involving privacy concerns, and wanting to retain my general predisposition to change my mind on all matters of opinion. If you believe you figured out my personal stance on any political issue, either you’ve misread it or I’ve failed to express myself properly; please, try not to read too much into it. Focus on the topics at hand.
So, without further ado, let’s start from the beginning: If a highly capable actor wanted to induce large-scale changes in a society, how would they go about it? How would they coordinate apparently independent efforts in a covert but effective way?
The Need for a Large-Scale Model of Society
After millennia of developments in the spread of disinformation, and decades of digital adaptations and improvements, it seems very safe to assume that the capabilities of highly capable actors (e.g. nation-states) have evolved beyond randomly distributing disinformation and hoping to achieve their goals. Careful long-term planning and large-scale coordination will always exert greater influence than random interjection on specific issues.
To coordinate a large-scale propagandistic operation, a large-scale model of the target is required. To maximize the effectiveness of this model through digital means, it must possess 4 fundamental properties. It must be:
- Actable: The insight provided by the model must help make decisions, carry them out, and track their effectiveness on an ongoing basis
- Detailed: If the model represents a society in a lot of detail, it’s easier to identify the most effective channels of information transfer to exploit. The higher granularity you can achieve in terms of data analysis and classification, the more easily you will be able to exploit those channels
- Informed: To help make any operation more dynamic and effective, we need to feed as much information into the system as possible, as quickly and often as we can
- Quantitative: Humans are able to make decisions based on the careful observation of ethereal concepts like personality traits, opinions, inequality, etc. In order to get computers to make decisions based on that information, we need to provide the software with a quantified representation of those ethereal concepts; If we manage to do it, the dynamism and effectiveness of a campaign can be taken far beyond purely human capabilities
If we’re going to ponder about the objectives and methodologies of bad actors, building a model of our own would certainly help put things into perspective. Because I’m trying to develop a model that satisfies their needs, even if the actual models used by real-life actors are very different, I believe the insight they provide is likely to overlap significantly with our own.
Now, since humans are capable of independent thought, is it really possible to come up with a physical model that provides real and actable insight on the the behavior of human masses?
[Theory] Physics Models that Help Describe Human Behavior
A long time ago, I learned that scientists and engineers had been using modified fluid dynamics models to study how human crowds navigate confined physical spaces. As postulated by Helbing, et al. in 2001:
In mass evacuations, human behavior continues to be an important factor, but the individuals cannot affect the crowd dynamics individually. When the density of the crowd becomes critical, the group behavior dominates and the movement pattern will instead look more like a natural flow, which can be compared to a fluid.
Of course, as stated by Sadeq J. Al-nasur in 2006:
The drawback to this way of modeling is due to the assumption that pedestrians behave similarly to fluids. Pedestrians tend to interact among themselves and with obstacles in their model area, which is not captured by macroscopic models.
But even with those drawbacks, the potential usefulness of fluid modeling seems obvious when presented with visual examples from real life.
For instance, at this Chicago Marathon start, a chokepoint is introduced so participants will have enough space to naturally disperse and run comfortably. If pressure behind the chokepoint was allowed to build up unrestricted, the runners on the sides would be pushed into the barriers, and the ones in the middle pushed through the chokepoint at “high speed”; akin to the combustion gases shooting through a rocket engine’s nozzle. To control the pressure at the front, the organizers set up human barriers that segmented the runners before the start:
In this other case, during a concert, a huge wave of humans pushing each other (a “crowd surge”) suddenly formed. This video has been studied by multiple scientific papers, as it effectively shows how the wave moves through the crowd, and how it reflects on the perimetral barriers until eventually dissipating:
Through careful consideration, these fluid models allow venue designers and event organizers to introduce segmentations and obstacles, design the perimetral shape of the location, etc. to limit the pressure and the motion of waves traveling through the crowd, hence increasing everyone’s safety. Human nature does impose some limitations on the model, but -given a critical mass of individuals- it still provides real and useful insight.
Similarly, even though it’s hard to predict whether an individual will accept an idea as valid, developing a model that provides actable insight on how a large number of people will react to certain informational conditions might be possible to some extent. What would that model look like? Let’s consider it.
Modeling Society as a Continuously Self-Regulated Control System
Developing models of society is nothing new. Sociologists, as well as scientists in other fields, have been doing it forever. Take, for instance, this working model of “the human ecosystem” published in 1996 by G.E. Machalis et al.:
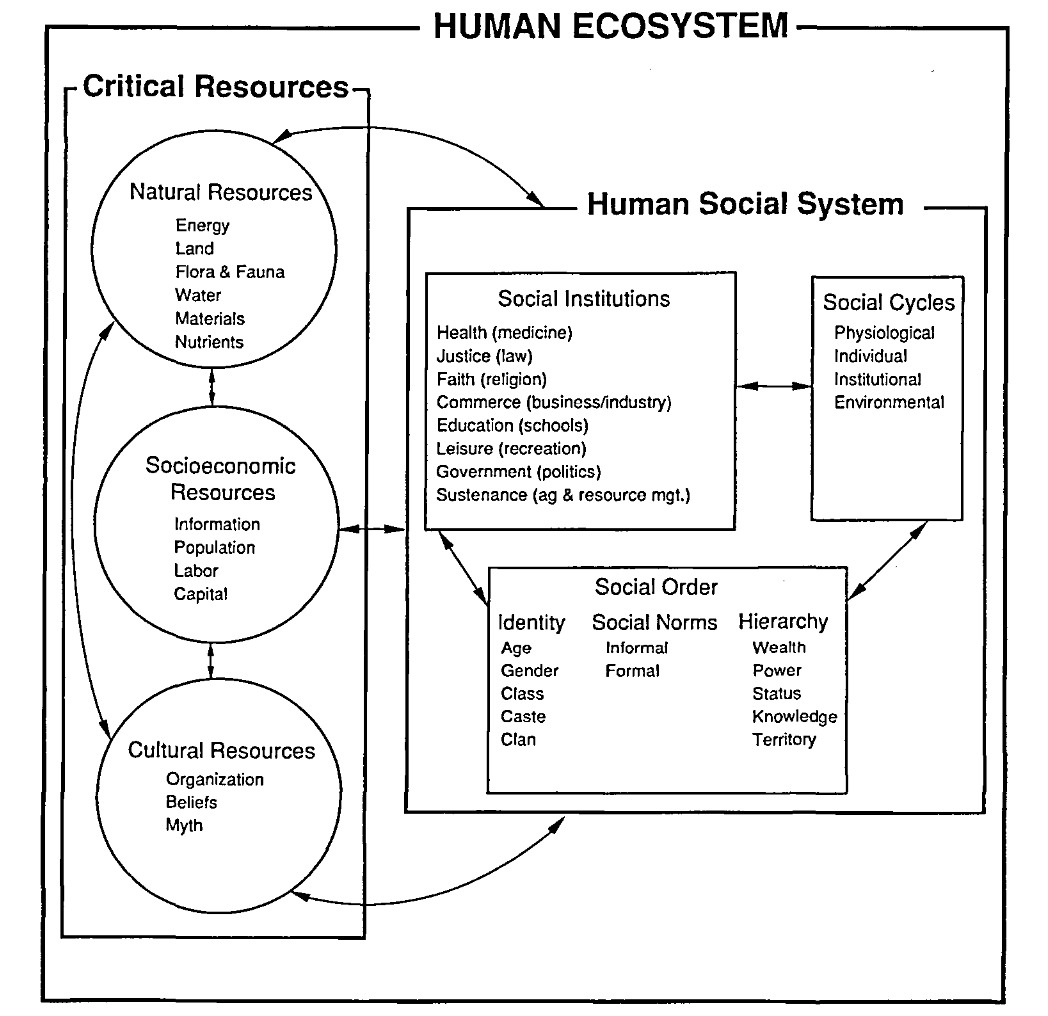
That model, among many others, focuses mostly on being highly detailed in order to help us understand society at a large scale. Unfortunately, they lack the continuous aggregation of information and quantitative representation of factors required to make it actable for propagandistic purposes.
We need our model to focus on the continuous flow and evolution of ideas and information, even if it’s at the expense of some macro-level details like natural resources. We’ll fit those missing details into the model as required, but we can forego them for now.
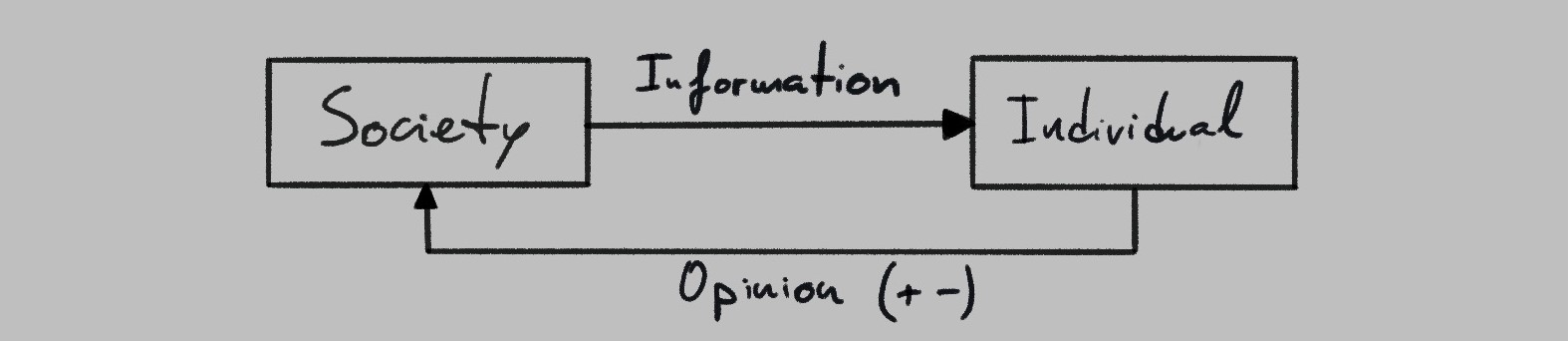
In a purely information-centered model, we can depict the relationship between individuals and society as follows: they absorb information from society, process it, and feed their conclusions back into society.
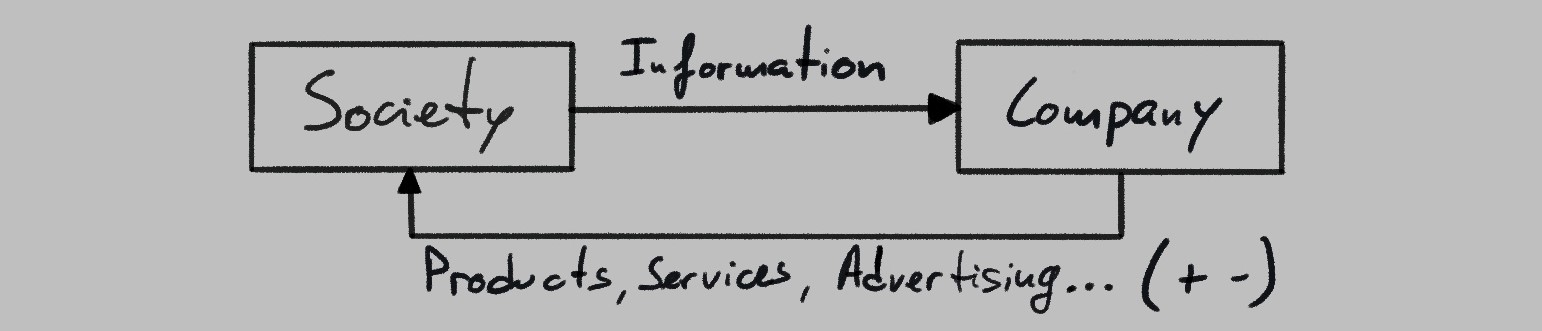
All kinds of groups and organizations aiming for societal change can be described similarly, from artists to armies. For instance, companies provide a vital role in society, but some have also been known to spread misinformation in order to downplay the negative aspects of their businesses, gain an advantage over competitors, or other self-serving purposes. As a result, companies in general contribute to society both positively and negatively:
And so on… An endless list of groups coming together to convince as many individuals as possible to adopt their lines of thinking. Some groups (e.g. physicists) pull a higher percentage of information from the natural world than society, but since society informs their perspective and process, they can still be modeled very similarly.
Overall, most individuals and groups pull most of their information from society, use it for some purpose, and feed their results/outcomes back into society. The combined extraction, processing, and aggregation of new information back into society from all the parties result in a continuously adapting society.
An engineer might describe a self-regulated system with such a significant amount of feedback as a closed-loop control system. What is that? You might ask…
[Theory] Fundamentals of Closed-Loop Control Systems
Control systems are used to manage the operating conditions of a device or system. To simplify a rather complex concept, let’s use an example.
Note: If you understand control systems, you’ll probably think this is grossly oversimplified; and you’d be right. For the purposes of these posts, there’s no point in going into a lot of detail; especially regarding transfer functions and the mathematical relationships they are used to calculate. I’ll focus on their most fundamental properties.
Say an engineer is designing an oven. They’re using a resistor to produce heat, and need to figure out how much current they should run through it to reach the desired temperature. They decide to run a certain amount of current through it, see which temperature the oven reaches, and then write the resulting temperature at that position in the dial.
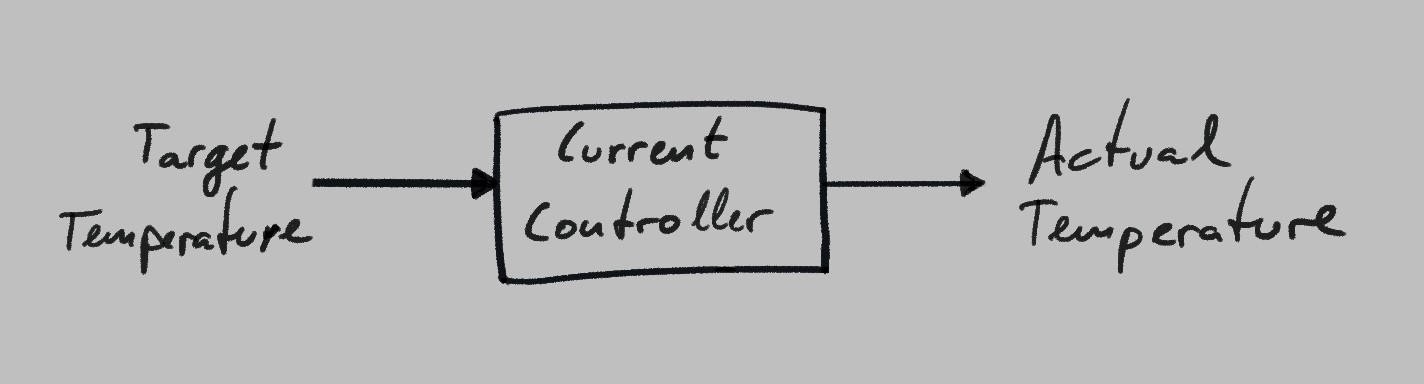
After running it for a while and monitoring the temperature, they come up with a result like this:
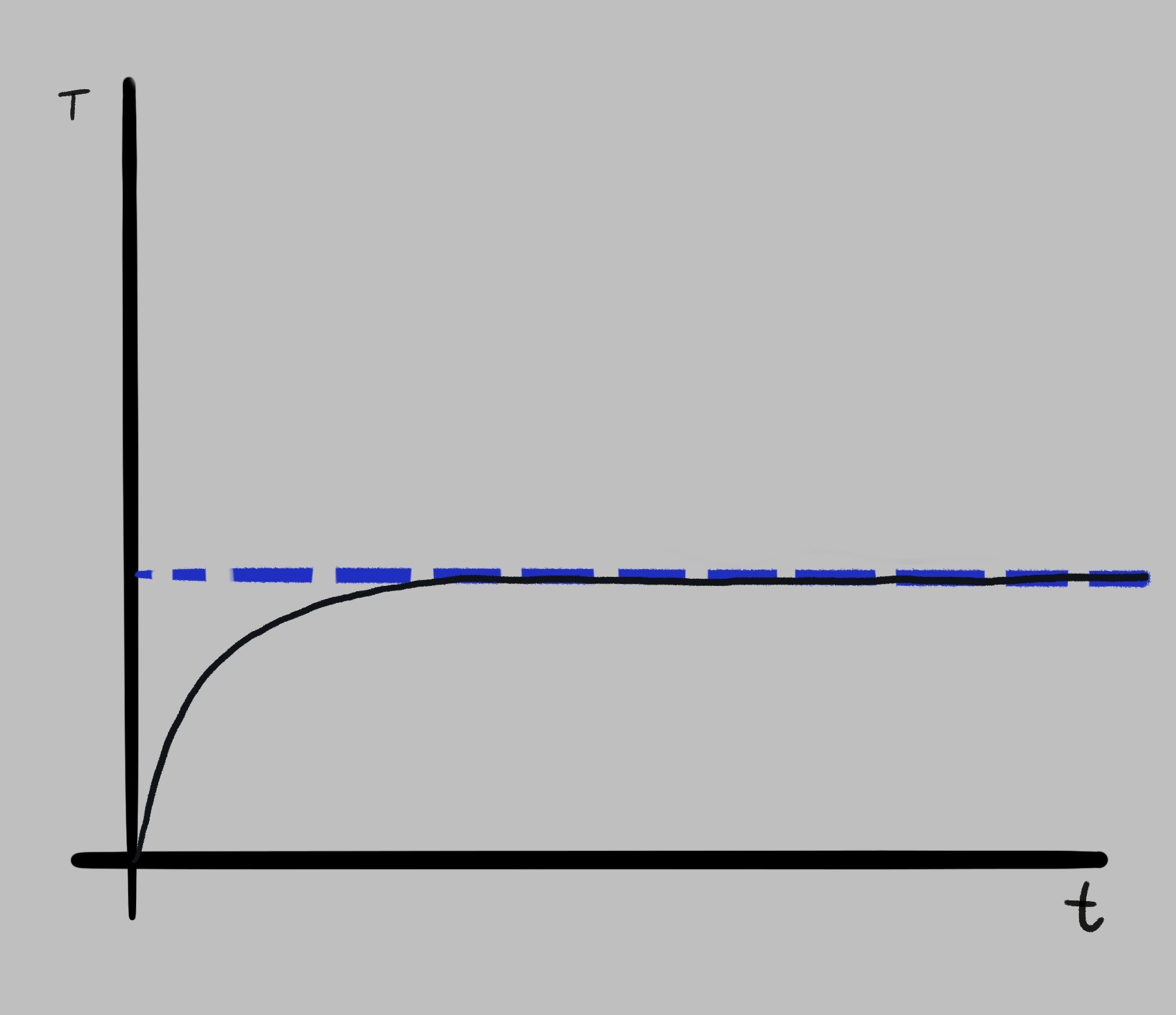
Assuming that X Amps will always take the oven temperature to Y degrees would be an easy way for the engineer to go home early. Just tell the user where to set some dial, and hope that the desired temperature will be reached.
But what if it doesn’t? Over time, the resistor and oven insulation will degrade, and the temperature response graph will start looking closer to this:
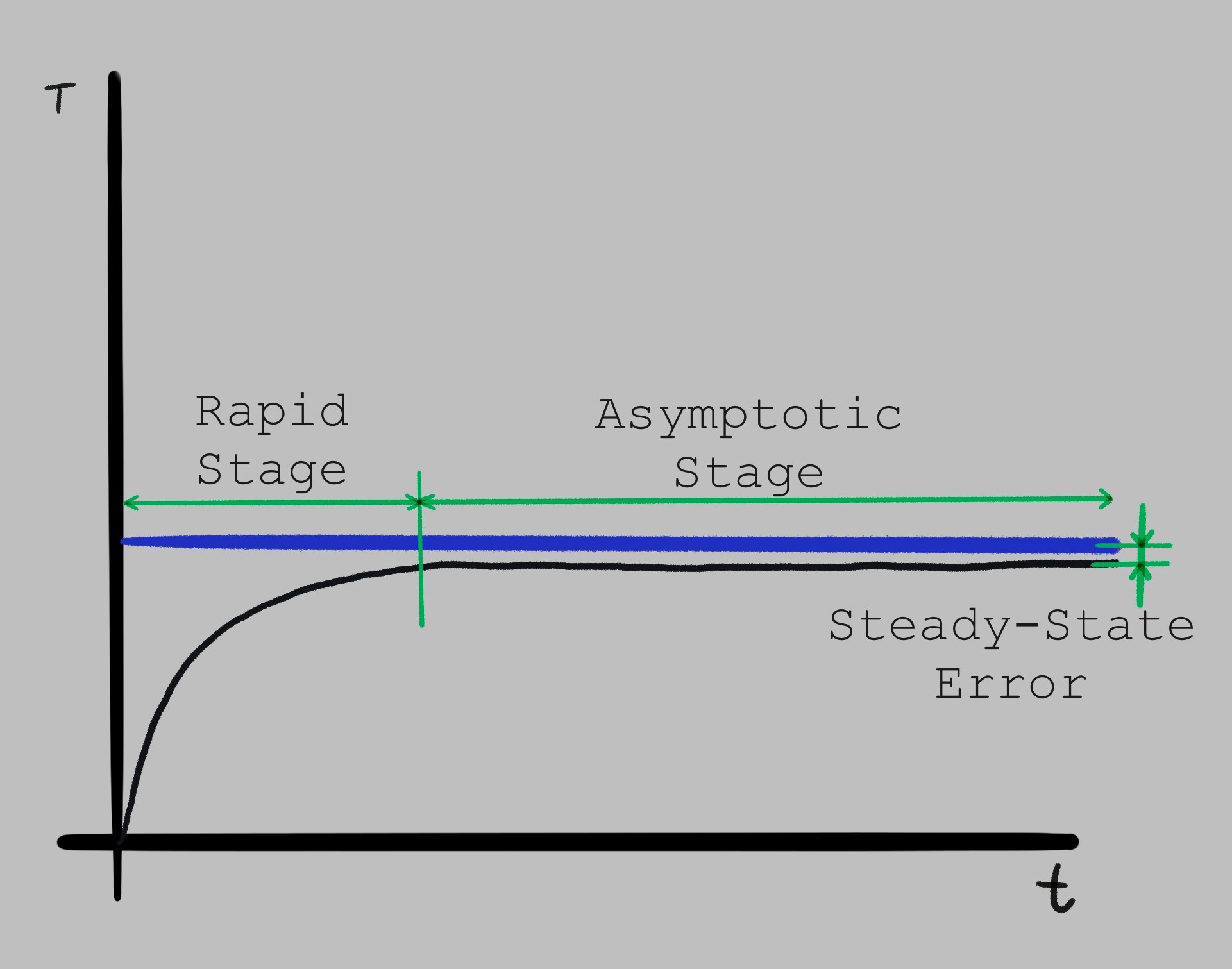
That “Steady-State Error” would become unacceptable over time, so the engineer needs to compensate for it.
In order to do it, the engineer needs to continuously monitor the actual temperature in the oven, and use that information to adjust the current going through the resistor. That information feedback would make the new design a closed loop of information and action, and would be modeled like this:
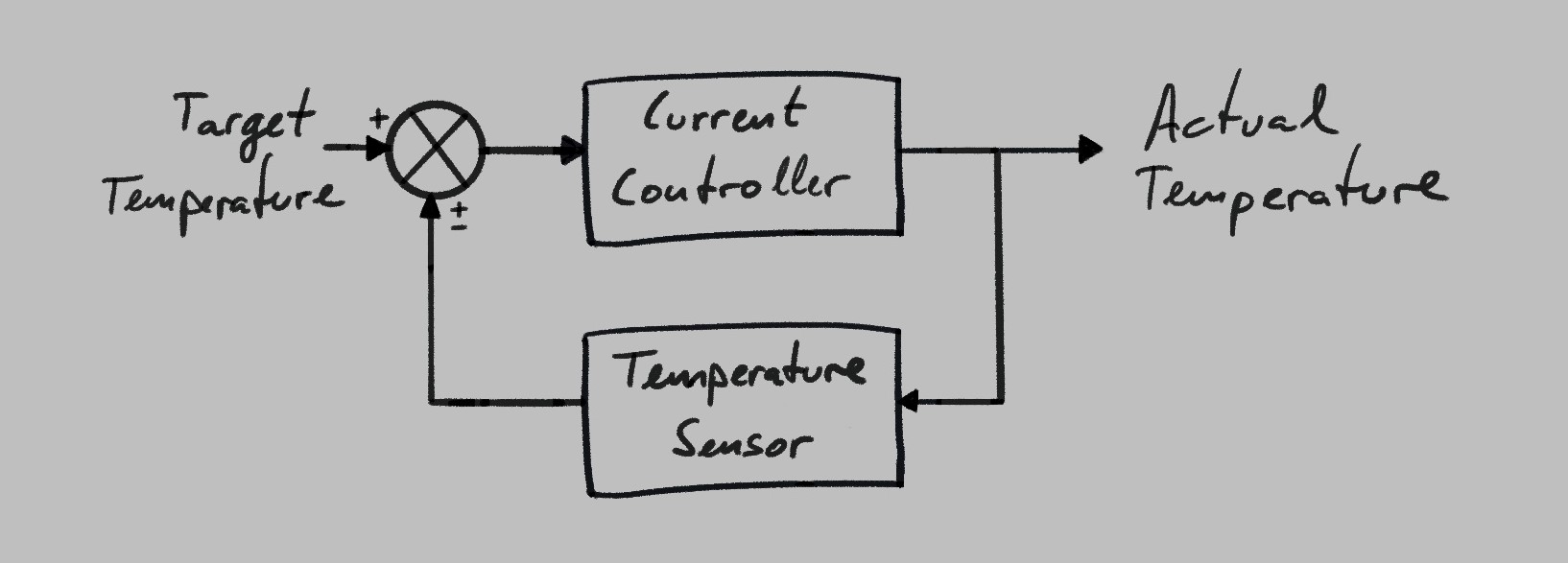
Knowing the actual temperature, the oven can now compensate for the degradation of the hardware over time. At the same time, it can temporarily push the resistor’s temperature past the desired temperature and dial it back down once the desired temperature is reached. This not only allows for the effective elimination of the Steady-State Error, but also allows the oven to reach the target temperature more quickly. After implementing the closed-loop control algorithm, and fine-tuning its configuration to use aggressive overshoot, they run a new test and the actual temperature of the oven looks more like this:
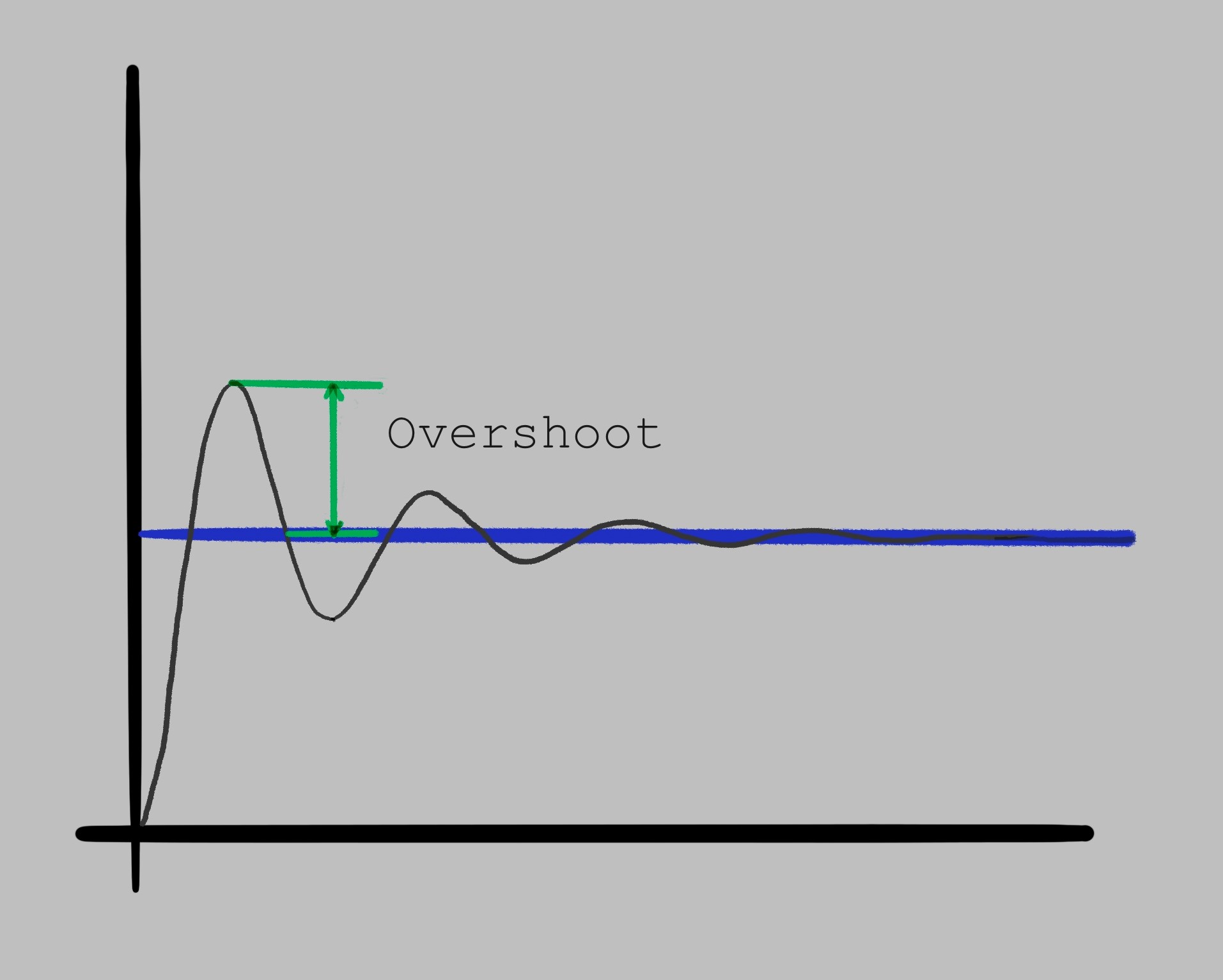
The trade-off for that speed and accuracy is having to deal with the negative consequences of repeatedly overshooting the target temperature. The resistor might degrade more quickly, some part of the oven might go above its maximum rated temperature and burn out, whatever is in the oven would reach temperatures above the desired one, etc. Overshoot can open the system to great risk through many possible considerations. Let’s consider some of them:
- Overshooting is inherently risky when dealing with delicate systems or substances
- E.g. Overshooting the temperature of a cooking oven can be fine for some foods, while burning/spoiling others
- Aggressive overshoot can accelerate the long-term degradation of individual
system parts. That degradation can eventually become catastrophic.
- E.g. an oven door exploding due to overly aggressive heat cycling over time to stabilize itself, resulting in an overall destabilization of the system
- Improper design or configuration of an overshooting system can make it unstable
to the point of self-destruction
- E.g. Systems that take quick, aggressive action to compensate for changes detected by a slow or imprecise sensor
- Harmful feedback loops can result in a system failure, both progressively
or abruptly.
- E.g. This cop trying to stabilize a segway, while the segway tries to stabilize itself, resulting in an overall destabilization of the system:
And that’s the final challenge for the engineer. To figure out exactly how to fine-tune the control system, in order to achieve fast change while minimizing the risks associated with over-shoot.
With all that in mind, if we assume society and public opinion to behave as a closed-loop control system, it could (simplistically) be modeled like this:
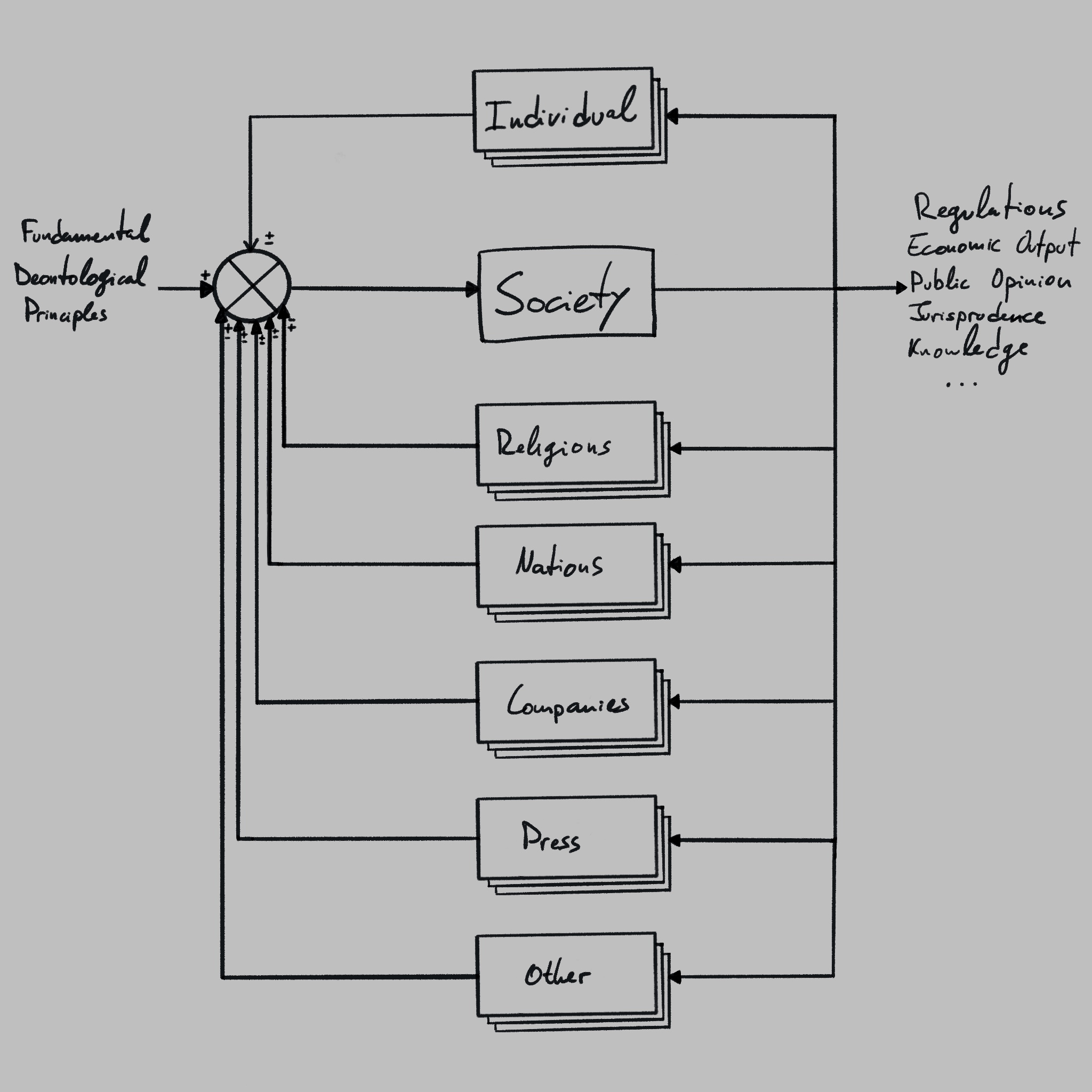
If we want to use this model to evaluate and exploit group inequalities, we need the Y-axis of the graph to represent the power dynamics between those groups.
I’ll go into more detail regarding how to define, measure, and exploit those power dynamics in the next post. For now, let’s focus on the fundamentals. It’s easy to differentiate between the most fundamental sources of inequality:
- Legal inequality - Differences in the letter of the law, regarding the rights and responsibilities assigned to each group
- Enforcement inequality - Differences in how the law is enforced by the police, the judicial system, plus groups and individuals in positions to enforce laws and other rules
- Cultural inequality - Differences in the attitudes and behavior regarding the treatment of one social group with respect to another
Reducing all inequality to 3 primary sources is an obvious over-simplification of a very complex topic. For now I’m leaving out economic and political sources of inequality, among others. Mostly because they can often be traced back to some of the ones I’ve described as “primary”. I might go into further detail in the next posts.
For a little more detail, we can establish a “privilege scale” between any 2 groups,
where 0 means the individuals of the underprivileged group are the target
for genocide, and 10 means the roles are completely reversed and the
privileged group becomes the target for genocide.
- Genocide of the Underprivileged Group
- Enslavement of the Underprivileged Group
- Fewer rights than the Privileged Group
- Equal rights, but harsher enforcement than the Privileged Group
- Equal rights, cultural downsides
- Equal rights, equal responsibilities, identical cultural status. Truest, purest meritocracy
- Equal rights, cultural upsides
- Equal rights and responsibilities, but enforced less heavily than the Privileged Group
- More rights than the originally Privileged Group
- Enslavement of the originally Privileged Group
- Genocide of the originally Privileged Group
Each specific idea, opinion, or fact can be assigned a value within that scale. The overall power dynamics between the groups will be a weighted average of all those factors.
Since any value in the scale represents a relationship between the positions
of each group, I usually refer to the Y-axis of the graph as the “Privilege Quotient”,
or PQ.
So what insight could we gain from such a model? Let’s try to extrapolate the properties and characteristics of a regular closed-loop control system with our sociologic equivalent.
Steady-State Error: Long-term Risks of Overly Conservative Approaches
When it comes to enacting social progress, aiming for equality without overshoot is probably the safest approach. It’s the best way to avoid the volatility introduced by overshoot into the system, while slowly conceding points to avoid the radicalization of underprivileged groups. In terms of social discussion, it’s also the best way to maintain civility, and to avoid radical counterpoints from the contrapositive groups and individuals.
But as discussed earlier, avoiding overshoot entirely generally results in an asymptotic approach towards equality: An ever-approaching trend line that will never reach equality as defined by the majority of individuals.
As years/decades/centuries/millennia pass without achieving all desired results, a growing sentiment of impatience and dissatisfaction among the aspiring groups is to be expected; especially as new generations grow up without having experienced the large inequality characteristic of the rapid stage. Those new generations, particularly while they’re young, will use whichever power they can gather to fight inequality, regardless of “how much worse it used to be”
And why shouldn’t they? Why should underprivileged groups simply accept that fate for any indeterminate, long-lasting period of time? Aiming for overshoot in order to eliminate the Steady-State Error and achieve equality ASAP is every individual’s prerogative.
But, while overshooting is a legitimate strategy to accelerate progress and reach a goal, consistently disregarding its risks is asking for trouble. Let’s evaluate those risks.
Overshoot: Risks and Rewards
The advantages of overshoot have been established by now: It’s a way for the system to reach its target more quickly, and to allow for the elimination of steady-state error. Sounds great.
Risks, on the other hand, are not so straightforward to consider. Essentially, a system that does not aim to keep itself within the absolutely safest conditions at all times is more vulnerable to volatility-induced degradation, malfunctions, and death. I’ll go into more detail regarding the specific risks to society in the next part, when I describe how malicious actors can exploit them.
Just like aiming for overshoot is a legitimate way to achieve social equality, opposing overshoot is a legitimate way to maintain social stability. As such, opposing overshoot is also every individual’s prerogative. And so, two opposing political principles are described by our model:
- Progressivism:
- Downplay/ignore overshoot risks
- Emphasize/exaggerate steady-state error
- Set a high bar for equality enforcement (laws or collective behaviors to be implemented in a society, for the sake of equality)
- Conservativism:
- Emphasize/exaggerate overshoot risks
- Downplay/ignore steady-state error.
- Set a low bar for equality enforcement
By identifying which school of thought each individual adheres to, and understanding which issues cause the most dissent among them, it becomes much easier to manipulate both groups into increased radicalization towards each other. For starters, just amplify disparate opinions (the more radical, the better), and silence or downplay all points of agreement. The more people you convince to adopt radical points of view, the more they will amplify your radical message, which will help radicalize more people on both sides, growing the harmful feedback loop.
Find every other point of dissent in a society, apply the same manipulation methodology, and you should be able to start orchestrating some real damage to the overall society and its output.
In the Next Post…
As a theoretical model, this closed-loop control system can only be accurate to a certain degree. Given my lack of mathematical proof, and the huge over-simplifications presented for the sake of brevity, how much you trust it is completely up to you.
Even if you don’t trust the theoretical model at all, I hope you consider the potential practical applications I’ll start laying out in the next post.
- Is it really possible to use the model to coordinate societal manipulation at a large scale?
- What does any of this have to do with the weaponization of social movements?
- How can a malicious actor exploit the risks of overshoot and steady-state terror in order to negatively influence a society?
- How does the current technological landscape help or hinder the stability of modern societies?
Those are some of the questions I’ll aim to answer, while adding further details to the model.
References
Regarding the use of fluid dynamics models to understand crowd behavior:
- Mass evacuation - human behavior and crowd dynamics
- Self-Organizing Pedestrian Movement
- New Models for Crowd Dynamics and Control
- Evacuation With Obstacles in Real-Time using Crowd Simulation
- Using fluid dynamic concepts to estimate species movement rates in terrestrial landscapes
Regarding the development of societal models:
Regarding online privacy and social networks:
如有侵权请联系:admin#unsafe.sh