经常有同学在微信群里面咨询,如何使用大模型从非结构化的信息里面提取出结构化的内容。最常见的就是从网页源代码或者长报告中提取各种字段和数据。
最直接,最常规的方法,肯定就是直接写Prompt,然后把非结构化的长文本放到Prompt里面,类似于下面这段代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from zhipuai import ZhipuAIclient = ZhipuAI(api_key="" ) response = client.chat.completions.create( model="glm-4-air-0111" , messages=[ {"role" : "system" , "content" : '''你是一个数据提取专家,非常善于从 从长文本中,提取结构化的数据。 ''' }, {"role" : "user" , "content" : '''你需要从下面的文本中,提取出姓名,工资,地址,然后以JSON格式返回。返回字段示例:{"name": "xxx", "salary": "yyy", "address": "zzz"}.只需要返回JSON字符串就可以了,不要解释,不要返回无关的内容。 """ 长文本 """ ''' } ], ) print (response.choices[0 ].message)
如果你每次只需要提取一两个数据,用这种方式确实没什么问题。不过正如我之前一篇文章《一日一技:超简单方法显著提高大模型答案质量》 中所说,返回的JSON不一定是标准格式,你需要通过多种方式来强迫大模型以标准JSON返回。并且要使用一些Prompt技巧,来让大模型返回你需要的字段,不要随意乱编字段名。
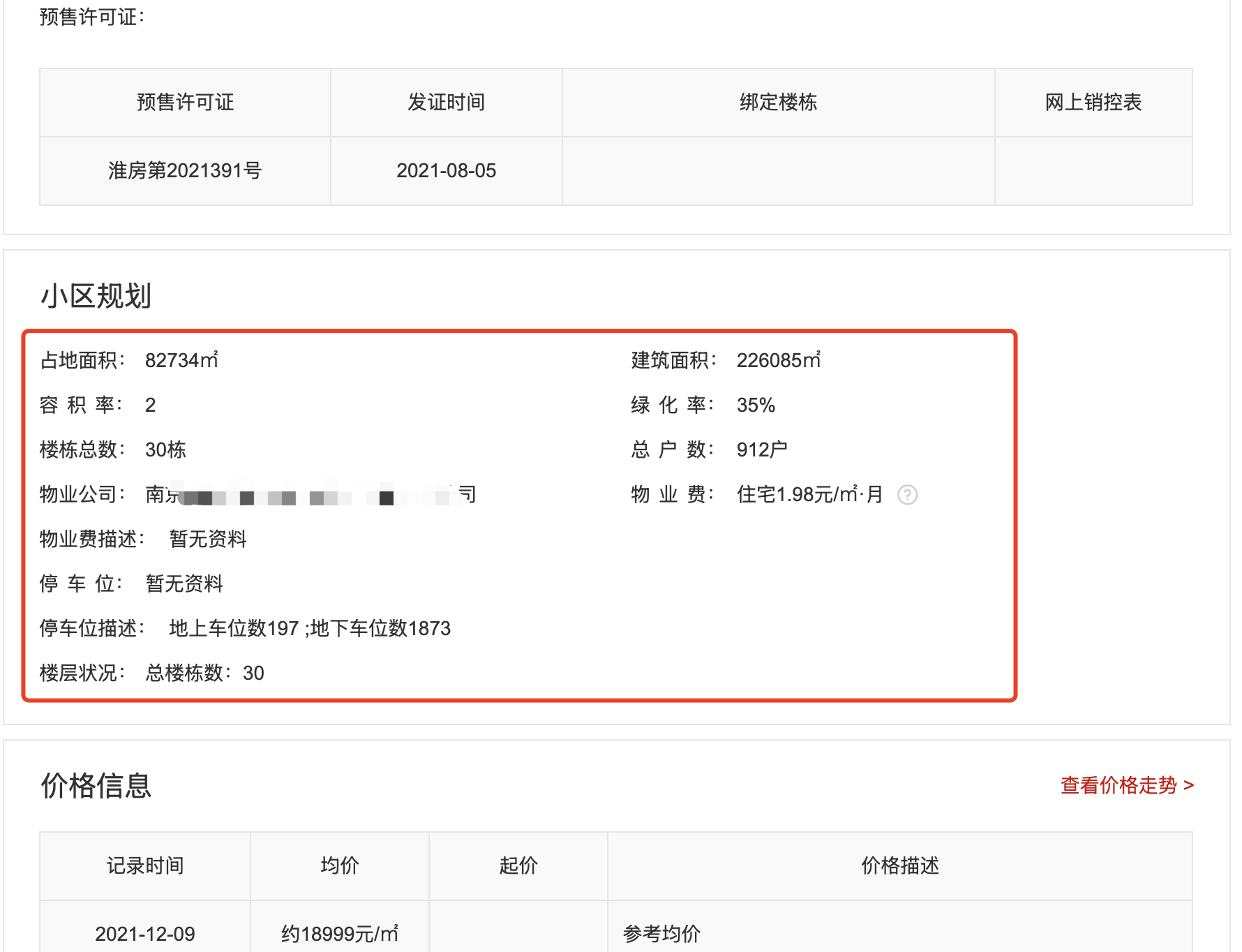
当你需要提取的数据非常多时,使用上面这种方法就非常麻烦了。例如我们打开某个二手房网站,它上面某个楼盘的信息如下图所示:
一方面是因为字段比较多,你使用纯文本的Prompt并不好描述字段。另一方面是HTML原文很长,这种情况基于纯Prompt的提取,字段名会不稳定,例如占地面积,有时候它给你返回floor_area有时候返回floorArea有时候又是其他词。但如果你直接在Prompt给出一个字段示例,例如:
1 2 3 4 5 6 7 8 9 ……上面是一大堆描述…… 返回的字段必须按如下示例返回: { "floor_area": 100, "building_area": 899 ... }
有时候你会发现,对于多个不同的楼盘,大模型返回给里的floor_area的值都是100,因为它直接把你的例子中的示例数据给返回了。
如果你只是写个Demo,你可能会觉得大模型真是天然适合做结构化数据的提取,又方便又准确。但当你真的尝试过几百次,几千次不同文本中的结构化数据提取后,你会发现里面太多的坑。
好在,Python有一个专门的第三方库,用来从非结构化的数据中提取结构化的信息,并且已经经过了深度的优化,大量常见的坑都已经被解决掉了。配合Python专门的结构化数据校验模块Pydantic,能够让提取出来的数据直接以类的形式储存,方便后续的使用。
这个模块叫做InstructorPydantic中定义好结果的数据结构,就能从长文本中提取数据。并且代码非常简单:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import instructorfrom pydantic import BaseModelfrom openai import OpenAIclass ExtractUser (BaseModel ): name: str age: int client = instructor.from_openai(OpenAI()) res = client.chat.completions.create( model="gpt-4o-mini" , response_model=ExtractUser, messages=[{"role" : "user" , "content" : "John Doe is 30 years old." }], ) assert res.name == "John Doe" assert res.age == 30
当然,正如我前面说的,一个小小的Demo能够完美运行并不能说明任何问题,我们要使用更多的实际例子来进行测试。假设我们的场景就是爬虫解析HTML,从上面的二手房网站提取房屋信息。
考虑到大部分情况下,HTML都非常长,即便我们提前对HTML代码做了精简,移除了<style>、<script>等等标签,剩余的内容都会消耗大量的Token。因此我们需要选择一个支持长上下文,同时价格又相对便宜的大模型来进行提取。
正好智谱 最近升级了GLM-4-Air系列大模型,最新的GLM-4-Air-0111模型,Token费用直接减半,每1000 Token只需要0.0005 元,每100万Token只需要5毛钱。而模型的智力跟旗舰模型GLM-4-Plus相差不大,因此非常适合用来做数据提取的任务。
Instructor本身不直接支持智谱的模型,因此需要使用它提供的LiteLLM配合智谱的OpenAI兼容接口来实现对接。
首先使用pip命令安装支持LiteLLM的Instructor:
1 pip install 'instructor[litellm]'
然后通过下面这样的代码就可以借助LiteLLM来链接智谱大模型。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import instructorfrom litellm import completionclient = instructor.from_litellm(completion) resp = client.chat.completions.create( model="openai/glm-4-air-0111" , api_key="对应的API Key" , api_base="https://open.bigmodel.cn/api/paas/v4/" , max_tokens=1024 , messages=[ { "role" : "user" , "content" : html, } ], response_model=HouseInfo, )
其中的HouseInfo定义的类如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from pydantic import BaseModel, Fieldclass HouseInfo (BaseModel ): floor_area: int = Field(description="占地面积" ) building_area: int = Field(description="建筑面积" ) plot_ratio: int = Field(description="容积率" ) greening_rate: int = Field(description="绿化率" ) total_buildings: int = Field(description="楼栋总数" ) total_households: int = Field(description="总户数" ) property_management_company: str = Field(description="物业公司" ) property_management_fee: str = Field(description="物业费" ) property_management_fee_description: str = Field(description="物业费描述" ) parking_spaces: str = Field(description="停车位" ) parking_space_description: str = Field(description="停车位描述" ) floor_status: str = Field(description="楼层状况" )
这就是一个标准的Pydantic类,定义了字段的名字,类型和意义。在调用Instructor时,传入这个类,传入精简以后的网页源代码,就能直接从网页中提取出对应的字段了。完整的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import instructorfrom litellm import completionfrom pydantic import BaseModel, Fieldclass HouseInfo (BaseModel ): floor_area: int = Field(description="占地面积" ) building_area: int = Field(description="建筑面积" ) plot_ratio: int = Field(description="容积率" ) greening_rate: int = Field(description="绿化率" ) total_buildings: int = Field(description="楼栋总数" ) total_households: int = Field(description="总户数" ) property_management_company: str = Field(description="物业公司" ) property_management_fee: str = Field(description="物业费" ) property_management_fee_description: str = Field(description="物业费描述" ) parking_spaces: str = Field(description="停车位" ) parking_space_description: str = Field(description="停车位描述" ) floor_status: str = Field(description="楼层状况" ) client = instructor.from_litellm(completion) html = ''' 精简以后的HTML代码 ''' resp = client.chat.completions.create( model="openai/glm-4-air-0111" , api_key="你的API Key" , api_base="https://open.bigmodel.cn/api/paas/v4/" , max_tokens=1024 , messages=[ { "role" : "user" , "content" : html, } ], response_model=HouseInfo, ) print (resp.model_dump_json(indent=2 ))print (f'提取到的占地面积是:{resp.floor_area} ' )
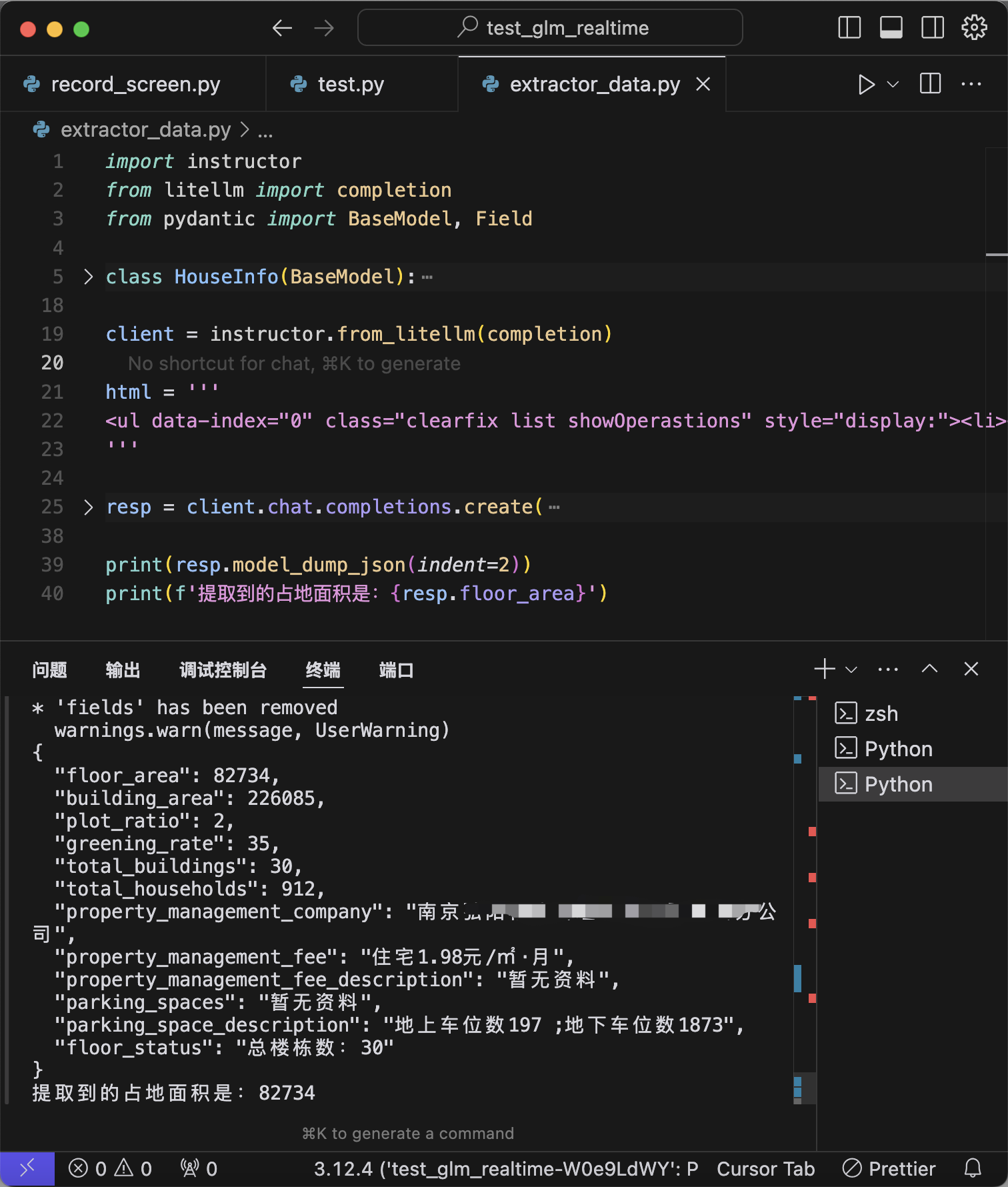
运行情况如下图所示:
得到的resp就是一个Pydantic对象,可以直接使用resp.floor_area来查看每个字段,也可以使用resp.model_dump_json转成JSON字符串。
Pydantic还可以指定一些字段是可选字段,一些字段是必选字段,也可以自动做类型转换,这些语法都可以在Instructor的Tips 中看到。
总结一下,使用Instructor,配合智谱GLM-4-Air-0111模型,可以大大提高结构化信息的提取效率。