2025-1-6 10:43:35 Author: www.vaadata.com(查看原文) 阅读量:7 收藏

Buffer overflow is one of the oldest and most exploited vulnerabilities. Despite this long history, they remain a major threat today.
Whether on servers or critical applications, the consequences of a buffer overflow can be devastating. In this article, we will explore in detail the principles of buffer overflow and the different types of attack. We will also detail the methods of exploitation, as well as the security best practices to protect against them effectively.
Comprehensive Guide to Buffer Overflow
What is Buffer Overflow?
A buffer overflow occurs when a process writes outside its allocated memory. This can overwrite critical data required for the program to function correctly.
C and C++ languages are particularly vulnerable to buffer overflows because of their manual memory management. They also have no built-in mechanisms to prevent overflows or unauthorised access.
Languages such as Java, Python and Perl, on the other hand, are less exposed. Their strong typing and memory management tools reduce these risks. However, they are not totally immune, and buffer overflows are still possible.
A buffer overflow can cause a programme to crash. But in some cases, an attacker can exploit this vulnerability to execute arbitrary code. This sometimes allows the attacker to take complete control of the system, depending on the privileges of the targeted process.
Before diving into the explanation of buffer overflows, let’s take a look at how a process’s memory works.
How Does Memory Work in a Process?
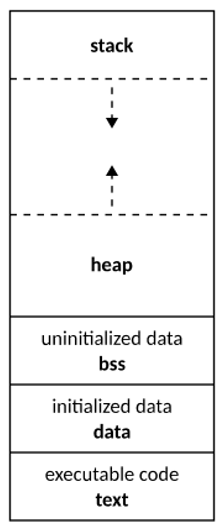
The memory of a process can be divided into five main segments:
- The code: This segment contains the program’s compiled instructions, ready to be executed in machine language.
- The data segment: This contains the initialised global variables. It has two zones: a read-only zone, for constants; and a read-write zone, for modifiable variables.
- BSS segment (Block Starting Symbol): Contains global and static variables initialised at zero or with no initial value defined in the code.
- The stack: This is used to manage function calls. It contains the function parameters, their local variables and the return address after execution. The stack is also organised in a ‘Last In, First Out’ (LIFO) fashion, which means that the last data added is the first to be removed.
- The heap: This is the area dedicated to dynamic memory allocation by the programmer. For example, with malloc() in C or new() in C++. Allocated memory persists until it is explicitly released.
This segmentation model is essential for understanding the vulnerabilities associated with buffer overflows. The diagram below shows how memory is organised for a program once it has been compiled:
To exploit buffer overflows, two areas are particularly targeted: the stack and the heap. These are the places where these vulnerabilities most frequently appear.
What are The Different Types of Buffer Overflow Attacks?
Buffer overflows fall into two categories: heap-based buffer overflow and stack-based buffer overflow.
For the example attacks and exploits below, we use a 32-bit architecture. The binaries have been compiled without modern security mechanisms such as stack canary and ASLR (Address Space Layout Randomization) for ease of exploitation.
Note that on a 64-bit architecture, the exploitation of buffer overflows differs, notably because of changes in the management of registers and memory addresses.
Stack-based buffer overflow
To understand a stack-based buffer overflow, it is essential to know how the execution stack works.
How the execution stack works?
When a function is called, several steps take place:
- Adding arguments to the stack: The arguments required to execute the function are placed on the stack, depending on the calling convention used.
- Saving the return address: The address to which execution should return after the function has finished is saved on the stack. This value is copied to the Extended Instruction Pointer (EIP) register. On 64-bit architecture, this register is called RIP (Re-Extended Instruction Pointer).
- Creating a new stack frame: A stack frame is created to store local variables and other function-specific information. The Extended Base Pointer (EBP) register points to the bottom of this frame, while the Extended Stack Pointer (ESP) register points to the top of the stack. Each function call generates a separate frame, making it easier to manage nested calls.
Stack-based buffer overflow attack
Let’s look at the following code:
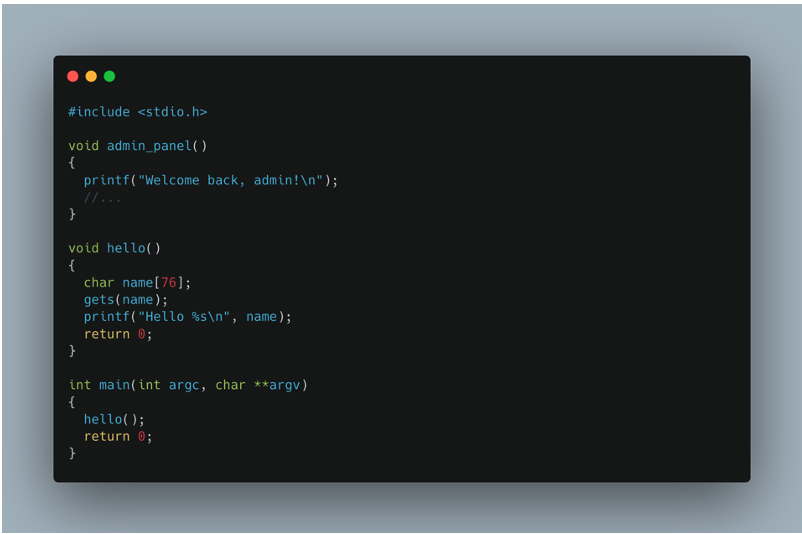
The attack consists of rewriting the address stored in the EIP register during execution of the hello() function. This allows the execution flow of the program to be hijacked and a specific function, such as admin_panel(), to be called.
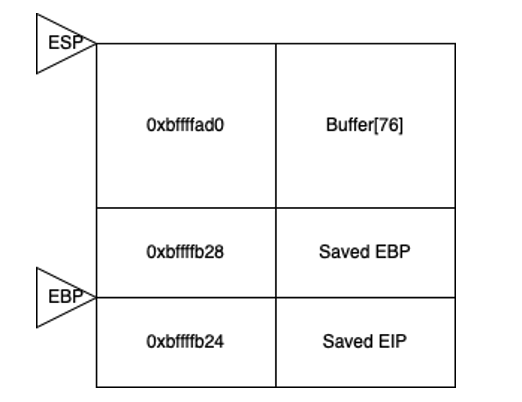
When execution enters the hello() function, the stack is structured as follows:
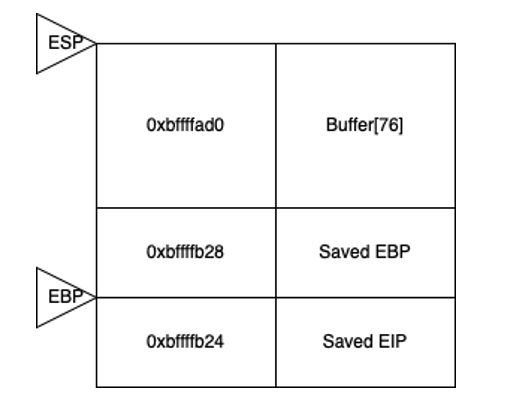
- The return address has been added to the stack
- The EBP register points to the base of the new stack frame
- Allocations for local variables have been made (here buffer)
- The ESP register points to the top of the stack frame
If a user enters a string of 80 characters, this exceeds the memory allocated to local variables (in this case 76 characters). The value pointed to by the EBP register is then overwritten.
If the user enters a longer string, say 84 characters, the attack directly targets the return address stored in EIP. By replacing this address with a new one, formatted in little-endian (byte order reversed), we can redirect execution to a specific function, such as admin_panel().
Heap-based buffer overflow
Exploiting a heap-based buffer overflow is slightly different from exploiting a stack-based buffer overflow. Although it is still an overflow where an entry exceeds the size allocated for the buffer, the memory area concerned is different. This is a dynamically allocated area.
A buffer overflow on the heap can have several consequences:
- Modification of adjacent variables: The overflowing data can overwrite nearby memory areas, thereby altering the logic of the program.
- Process crash: If the data corrupts a critical memory structure, this can lead to unstable behaviour and a program crash.
Let’s take the following example to better understand this attack:
The code above shows an example of a buffer overflow on the heap. Two buffers, named buffer and secret, are dynamically allocated in memory. Stored on the heap, these two buffers are adjacent to each other, which creates a situation conducive to an attack.
The gets() function is used to fill the buffer. However, gets() is vulnerable because it does not check the size of incoming data. If a string is entered that is too long, it will overwrite the value in secret.
The memory address of buffer is 0x00403160, and that of secret is 0x00403180. If a string longer than 32 characters (0x20 in hexadecimal) is entered, it exceeds the memory allocated to buffer and begins to overwrite secret. By manipulating this data, a new value can be forced into secret.
Depending on the architecture and implementation of dynamic allocation, the two variables may not be adjacent in memory. This may depend on the size of the buffers or the memory alignment.
Buffer overflow and DoS attacks
Let’s now look at an example of a buffer overflow that can be exploited to cause a denial of service.
This example is based on CVE-2021-44790, which concerns an attack on a variable of type size_t. This variable is used to allocate a buffer, which is then manipulated in the memcpy() function.
Here is the vulnerable code:
Due to the overflow, the allocated buffer has a size of 0, which causes a SEGMENTATION FAULT. This means that the program is trying to access a forbidden or non-existent memory area.
A variable of type size_t is used to determine the size of the buffer to be allocated. Because of the overflow, the allocated size becomes 0, which leads to a SEGMENTATION FAULT. The program then tries to access a memory area that does not exist or is protected, causing the process to crash.
To reproduce this vulnerability, we installed the vulnerable version of Apache (2.4.51) in a Docker environment. We configured the server to exploit this vulnerability, which manifests itself when the mod_lua module’s multipart parser is used. In addition, we added a Lua file to the root of the server. This file calls the r:parsebody() function and simply returns ‘Hello World!
Once the environment has been configured, we check that the server is running correctly.
We used the following command to exploit the vulnerability:
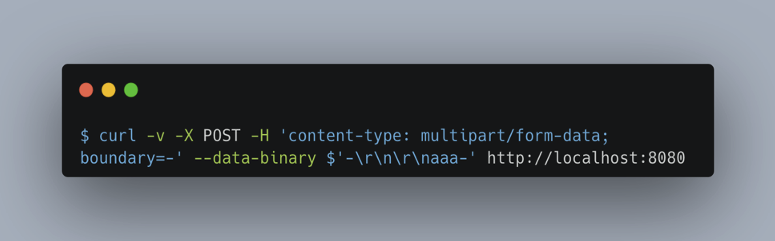
On the server side, the size of the allocated buffer is calculated as a function of the size of the request body and the position of the CLRF (\r\n), which is supposed to mark the end of the HTTP request.
However, due to the buffer overflow, the allocated buffer becomes size 0, which causes erroneous behaviour.
When the request is sent, the server crashes, resulting in a server side SEGMENTATION FAULT error:
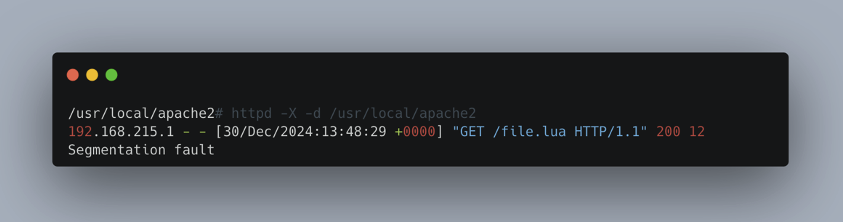
Once this vulnerability has been exploited, the server becomes inaccessible, preventing any service from running.
Buffer overflow and command execution: StageFright
In July 2015, a critical vulnerability was discovered in the Stagefright multimedia library, written in C++, used by Android phones from versions 2.2 (Froyo) to 5.1.1 (Lollipop).
At the time, around 95% of Android phones, or some 950 million devices, were vulnerable.
Exploiting this vulnerability did not require any user interaction. All the attacker needed was the victim’s telephone number. By sending an MMS or any other specially crafted multimedia file, the attacker could execute remote commands on the victim’s phone.
Impact of Buffer Overflow Attacks
The consequences of a buffer overflow can be varied:
- Server crash: Memory corruption can cause the process to stop abruptly. This can lead to unexpected behaviour such as infinite loops or fatal errors.
- Execution of arbitrary commands: Successful exploitation could allow an attacker to run commands on the vulnerable system.
- Opening to other vulnerabilities: A remote command execution can be used as an entry point. The attacker can exploit other vulnerabilities to escalate privileges, steal sensitive data or take full control of the system.
How to Prevent Buffer Overflow Attacks?
There are several methods for protecting against buffer overflow attacks:
- ASLR (Address Space Layout Randomization): This technique randomises the layout of memory areas (stack, heap, libraries). This complicates exploitation, as an attacker has to guess the targeted memory addresses.
- NX (Non-Executable Stack): This protection prevents code from being executed in areas not intended for this purpose, such as the heap and stack. Even if an attacker injects malicious code, they will not be able to execute it.
- SSP (Stack Smashing Protector): The SSP adds a random value (canary) before the stack return address. If this value is modified, the programme stops to prevent the attack. However, workarounds exist.
- Secure functions: Certain functions such as
gets,strcpy,strcatormemcpyare vulnerable. It is advisable to use secure alternatives to avoid overruns. - Regular updates: Keeping your software up to date is essential. New vulnerabilities are frequently discovered. For example, in December 2024, 18 CVEs related to buffer overflows were published with a CVSS score greater than 9.
Author: Théo ARCHIMBAUD – Pentester @Vaadata
如有侵权请联系:admin#unsafe.sh