大约三年前,我写了一篇分析 PHP 5 中数组的内存使用情况的文章。即将到来的 PHP 7 作为我工作的一部分,我重点关注于优化数据结构的大小以及内存分配上,为此重写了 Zend 引擎的大部分的内容。在这篇文章中,我将对新的 HashTable 实现进行概述,并说明为什么它比以前的实现更高效。
为了测量内存利用率,我将会使用下面的脚本创建一个包含 100000 个不同整数的数组:
$startMemory = memory_get_usage();
$array = range(1, 100000);
echo memory_get_usage() - $startMemory, " bytes\n";
下面这张表格展示了使用 PHP 5.6 和 PHP 7 在 32 位和 64 位系统上的内存使用情况:
| 32 bit | 64 bit
------------------------------
PHP 5.6 | 7.37 MiB | 13.97 MiB
------------------------------
PHP 7.0 | 3.00 MiB | 4.00 MiB
可以看到,PHP 7 中的数组在 32 位上使用的内存要比 PHP 5.6 少 2.5 倍,在 64 位(LP64)上要少 3.5 倍,这是相当可观的性能提升。
Hashtable 介绍
从本质上讲,PHP 的数组是有序字典,即一个表示键/值对的有序列表,其中键/值映射是使用 Hashtable 实现的。
Hashtable 是一种非常常见的数据结构,它本质上解决了计算机只能直接表示连续的整数索引数组的问题,而程序员往往希望使用字符串或其它复杂类型作为键。
Hashtable 背后的概念非常简单:字符串通过哈希函数(hash function)处理后,哈希函数会返回一个整数(哈希值),然后将这个整数作为「普通」数组的索引。这里有一个问题,两个不同的字符串的可以产生相同的哈希值,因为字符串的大小几乎是无限制的,而哈希值则受到整数大小的限制。因此,HashTable 需要实现某种冲突解决机制。
冲突解决机制主要有两种:开放寻址法,如果发生哈希冲突,元素将被存储在不同的索引中;拉链法,所有哈希值相同的元素被存储在一个链表中。PHP 使用的是第二种。
通常情况下,Hashtable 中的元素是没有明确的顺序的。元素在底层数组中的存储顺序取决于哈希函数(hash function),并且非常的随机。但是这种行为与 PHP 数组的语义不一致:如果你遍历一个 PHP 数组,你将会按照元素的插入顺序取回元素。这意味着 PHP 的 Hashtable 实现必须支持一种额外的机制来记录数组元素的顺序。
旧的 Hashtable 实现
在这里,我只对旧的 Hashtable 实现做一个简短的概述,更全面的解释请看《PHP 内部实现》书籍中的 Hashtable 章节。
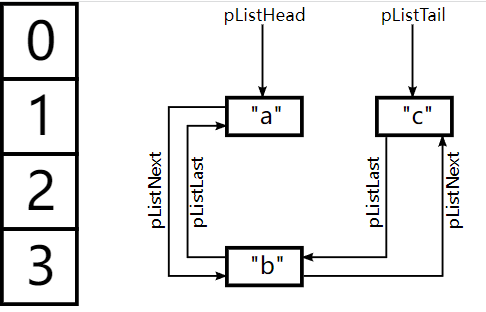
下面这张图从高层次的视角展示了 PHP 5 的 Hashtable 实现。

「冲突解决机制」链表中的元素被称为「bucket」,每一个 bucket 都是单独分配的。上面的图片中省略了这些 bucket 中存储的实际值(只展示了键)。值被存储在单独分配的 zval 结构体中,其大小为 16 字节(32 位)或 24 字节(64 位)。
上面的图片中没有展示的另一点是,冲突解决机制链表实际上是一个双向链表(使元素的删除变得简单)。除了冲突解决机制链表以外,Hashtable 还有另一个双向链表用来存储数组元素的顺序。对于按照顺序包含 “a”、“b”、“c” 的数组,该链表可能如下所示:
那么,为什么旧的 Hashtable 结构体在内存使用和性能方面都如此低效?有以下几个主要因素:
- bucket 需要单独分配。分配的速度非常慢,并且还需要 8/16 字节的分配开销。单独分配意味着 bucket 在内存中会更加分散,从而会降低缓存的效率。
- zval 也需要单独分配。同样,这也是很慢的,而且会产生额外的 header 开销。另外这需要每个 bucket 都保存一个指向 zval 的指针。因为旧的实现过于考虑通用性,所以实际上不只需要一个指针,而是两个指针。
- 两个双向链表导致每个 bucket 总共需要 4 个指针。仅此就已经占用了 16/32 字节。此外,遍历链表是一种非常缓存不友好(cache-unfriendly)的操作。
新的 Hashtable 实现试图解决(或者至少是改善)这些问题。
新的 zval 实现
在讨论新的 Hashtable 之前,我想快速地介绍一下新的 zval 结构体,并强调它与旧结构体的区别。zval 结构体定义如下:
struct _zval_struct {
zend_value value;
union {
struct {
ZEND_ENDIAN_LOHI_4(
zend_uchar type,
zend_uchar type_flags,
zend_uchar const_flags,
zend_uchar reserved)
} v;
uint32_t type_info;
} u1;
union {
uint32_t var_flags;
uint32_t next; /* 哈希冲突链表 */
uint32_t cache_slot; /* 缓存槽 */
uint32_t lineno; /* 行号(用于 ast 节点) */
} u2;
};
你可以忽略这个定义中的 ZEND_ENDIAN_LOHI_4 宏,它只是为了确保在具有不同字节序的机器上有一个可预测的内存布局。
zval 结构体有三个部分:第一个成员是 value。zend_value 联合体的大小为 8 字节,它可以存储不同类型的值,包括整数、字符串、数组等等。实际存储的内容取决于 zval 的类型。
第二部分是 4 个字节大小的 type_info,包括实际的类型(如 IS_STRING 或 IS_ARRAY),以及一些提供给该类型信息的附加标志。例如,如果 zval 存储的是一个对象,那么类型标志会说它是一个非常量(non-constant)、引用计数(refcounted)、垃圾回收(garbage-collectible)、不可复制(non-copying)的类型。
zval 结构体的最后 4 个字节通常是未使用的(它实际上只是显式填充,否则编译器会自动引入这种填充,即内存对齐)。然而在特殊情况下,这块空间被用来存储一些额外的信息。例如,AST 节点用它来存储行号,VM 常量用它来存储缓存槽索引,Hashtable 用它来存储冲突解决机制链表中的下一个元素。最后一部分对我们很重要。
如果你将其与之前的 zval 实现相比较,有一个区别特别明显:新的 zval 结构体不再存储 refcount。这背后的原因是,zval 本身不再被单独分配。相反,zval 直接嵌入到存储它的东西中(例如 Hashtable 的 bucket)。
虽然 zval 本身不再存储 refcount,但是字符串、数组、对象和资源这些复杂的数据类型仍然可以使用它。实际上,新的 zval 设计已经将 refcount(以及循环收集器的信息)移动到了数组、对象等复杂类型中。这种做法有很多优点,其中一部分优点如下:
- zval 存储简单值(例如布尔值、整数或浮点数)不再需要任何分配。因此,通过避免不必要的分配和释放以及提高缓存本地性,这节省了分配头开销并提高了性能。
- zval 存储简单值时,不需要存储 refcount 和垃圾回收根缓冲区(GC root buffer)。
- 我们需要避免双重引用计数。例如,之前的对象使用了 zval 的 refcount,又使用了一个额外的对象 refcount,这对于支持按对象传递的语义来说是必须的。
- 由于现在所有复杂的值都嵌入了 refcount,它们可以独立于 zval 机制而被共享。特别是现在还可以共享字符串。这对 Hashtable 的实现很重要,因为它不再需要复制 non-interned 字符串的键。
新的 Hashtable 实现
在所有前期准备工作结束后,我们终于可以看看 PHP 7 所使用的新的 Hashtable 实现。让我们先来看一下 bucket 的结构体:
typedef struct _Bucket {
zend_ulong h;
zend_string *key;
zval val;
} Bucket;
bucket 是 Hashtable 中的一个条目。它包含了你所期望的东西:哈希值 h,字符串键 key 和 zval 值 val。当键为整数时,整数会被存储在 h 中(在这种情况下,键和哈希值是相同的),并且成员 key 将会是 NULL。
如你所见,zval 直接嵌入到了 bucket 结构体中,因此它不需要单独分配,也就不会产生分配带来的开销。
Hashtable 的结构更加有趣:
typedef struct _HashTable {
uint32_t nTableSize;
uint32_t nTableMask;
uint32_t nNumUsed;
uint32_t nNumOfElements;
zend_long nNextFreeElement;
Bucket *arData;
uint32_t *arHash;
dtor_func_t pDestructor;
uint32_t nInternalPointer;
union {
struct {
ZEND_ENDIAN_LOHI_3(
zend_uchar flags,
zend_uchar nApplyCount,
uint16_t reserve)
} v;
uint32_t flags;
} u;
} HashTable;
bucket(即数组元素)存储在 arData 数组中。该数组的以 2 次方幂进行分配,数组大小存储在 nTableSize 中(最小值为 8)。元素的实际数量存储在 nNumOfElements 中。注意,这个数组直接包含 Bucket 结构体。以前我们使用一个指向单独分配的 bucket 的指针数组,这意味着我们需要执行更多次的分配和释放,必须要承担分配带来的开销,还要存维护额外的指针。
元素的顺序
arData 数组按照插入顺序存储元素。所以第一个数组元素将会被存储在 arData[0] 中,第二个存储在 arData[1] 中等等。任何时候都与所使用的键无关,只取决于插入的顺序。
因此,如果在 Hashtable 中存储 5 个元素,将使用插槽 arData[0] 到 arData[4],下一个空闲的插槽是 arData[5]。我们使用 nNumUsed 来记录这个数字。你可能会问:为什么我们要单独存储它,它和 nNumOfElements 不是一样的吗?
是的,但是只有在只执行插入操作的情况下,它们会是一样的。如果从 Hashtable 中删除了一个元素,我们显然不想移动 arData 中出现在被删除元素之后的所有元素,以便再次拥有一个连续的数组。相反,我们只是使用 IS_UNDEF zval 类型来标记已删除的值。
举个例子,思考下面的代码:
$array = [
'foo' => 0,
'bar' => 1,
0 => 2,
'xyz' => 3,
2 => 4
];
unset($array[0]);
unset($array['xyz']);
将会产生以下 arData 结构:
nTableSize = 8
nNumOfElements = 3
nNumUsed = 5
[0]: key="foo", val=int(0)
[1]: key="bar", val=int(1)
[2]: val=UNDEF
[3]: val=UNDEF
[4]: h=2, val=int(4)
[5]: NOT INITIALIZED
[6]: NOT INITIALIZED
[7]: NOT INITIALIZED
正如你所看到的,前五个 arData 元素已被使用,但是位置 2(键为 0)和位置 3(键为 'xyz')的元素已被替换成了 IS_UNDEF,这是因为它们被 unset 了。现在这些元素的存在只是在浪费内存。但是,当 nNumUsed 等于 nTableSize 时,PHP 将尝试压缩 arData 数组,删除沿途添加的任何 UNDEF 条目。只有当所有的 bucket 都包含一个值时,arData 数组才会被重新分配到两倍的大小。
与 PHP 5.x 中使用的双向链表相比,维护数组顺序的新方法有几个优点。一个明显的优势是,我们为每个 bucket 节省了两个指针,相当于 8/16 字节,此外,这意味着数组的迭代看起来大致如下:
uint32_t i;
for (i = 0; i < ht->nNumUsed; ++i) {
Bucket *b = &ht->arData[i];
if (Z_ISUNDEF(b->val)) continue;
// do stuff with bucket
}
这相当于对内存的线性扫描,这比遍历链表(在相对随机的内存地址之间来回)更高效。
目前的实现有一个问题,就是 arData 永远不会收缩(除非明确告诉它)。因此,如果你创建一个有几百万个元素的数组,之后将它们删除,那么这个数组仍然会占用大量的内存。如果利用率低于一定水平,我们也许应该把 arData 的大小减半。
HashTable 查找
到目前为止,我们只讨论了 PHP 数组如何表示顺序。实际上,Hashtable 的查找使用的是第二个数组 arHash,它由 uint32_t 类型的值组成。arHash 数组的大小与 arData 数组的大小相同(即 nTableSize),两者实际上都被分配在同一段连续的内存中。
从哈希函数(DJBX33A 是一种哈希算法,用于字符串类型的键)返回的哈希值是一个 32 位或 64 位无符号整数,这个整数值太大了,不能直接作为哈希数组的索引。我们首先需要使用模运算将其调整到 nTableSize 的大小范围内。我们使用 hash & (ht->nTableSize - 1) 代替 hash & ht->nTableSize,如果大小是 2 的幂也是一样的,不需要昂贵的整数除法运算。ht->nTableSize - 1 的值存储在 ht->nTableMask 中。
接下来,我们在哈希数组中查找索引 idx = ht->arHash[hash & ht->nTableMask],这个索引(idx)相当于冲突解决机制链表的头。因此,ht->arData[idx] 是我们要检查的第一个条目。如果键和我们要找的一样,那么就完成了查找。
否则,我们必须继续检查冲突解决机制链表中的下一个元素。该元素的索引存储在 bucket->val.u2.next 中,它是 zval 结构体的最后 4 个字节,这些字节在这个上下文中具有特殊的意义。我们继续遍历这个链表(使用索引而不是指针),直到找到正确的 bucket,或者命中 INVALID_IDX,这意味着查找的键对应的元素不存在。
在代码中,查找机制如下所示:
zend_ulong h = zend_string_hash_val(key);
uint32_t idx = ht->arHash[h & ht->nTableMask];
while (idx != INVALID_IDX) {
Bucket *b = &ht->arData[idx];
if (b->h == h && zend_string_equals(b->key, key)) {
return b;
}
idx = Z_NEXT(b->val); // b->val.u2.next
}
return NULL;
让我们考虑以下这种方法是如何改进以前的实现的:在 PHP 5.x 中,冲突解决机制使用基于指针的双向链表。使用 uint32_t 索引代替指针更好,因为它们的大小只有 64 位系统的一半。此外,在 4 个字节中,意味着我们可以将「next」链接嵌入到未使用的 zval 插槽中,因此我们基本上可以免费使用它。
我们现在使用的是单向链表,不再需要「prev」指针了。「prev」指针主要用于删除元素,因为当你删除某个元素的时候,你需要调整「prev」指针的「next」指针所指向的元素。但是,如果通过键删除元素,通过遍历冲突解决机制链表,你实际上已经知道前一个元素了。
少数情况下,删除发生在其它上下文中(例如,删除当前正在遍历的元素),将不得不遍历冲突解决机制链表找到前一个元素。但由于这是一个相当不重要的场景,我们更倾向于节省内存,而不是增加一个链表用于这种场景下查找前一个元素。
Packed Hashtable
PHP 中所有的数组都使用了 Hashtable。但是,在连续的、以整数为索引的数组(即真正的数组)这种比较常见的情况下,整个哈希过程没有多大意义。这就是为什么 PHP 7 引入了「Packed Hashtable」的概念。
在 Packed Hashtable 中,arHash 数组为 NULL,并且直接使用索引从 arData 中进行查找。如果你要找的键为 5,那么这个元素将位于 arData[5] 中,或者它根本就不存在。没有必要去遍历冲突解决机制链表。
注意,即使对于整数索引数组,PHP 也必须保持顺序。数组 [0 => 1, 1 => 2] 和 [1 => 2, 0 => 1] 是不一样的。Packed Hashtable 优化只有在键按升序排列时才起作用。它们之间可能有间隙(键不一定是连续的),但是它们要是呈递增趋势的。因此,如果元素以「错误」的顺序(例如反过来)插入到数组中,则不会使用 Packed Hashtable。
另外需要注意,Packed Hashtable 仍然存储大量无用的信息。例如,我们可以根据 bucket 的内存地址确定它的索引,因此 bucket->h 是多余的。bucket->key 的值始终为 NULL,因此它也只是在浪费内存。
我们保留这些无用的值以便于 bucket 使用相同的结构体,与是否使用 Packed Hashtable 无关。
这意味着迭代可以使用使用相同的 key。然而,将来我们可能会切换到「fully packed」的结构,如果可能的话,将会使用 zval 数组来实现。
空的 Hashtable
在 PHP 5.x 和 PHP 7 中,对于空的 Hashtable 都做了一些特殊处理。如果你创建一个空数组 [],很有可能你实际上不会插入任何元素。因此,arrData/arHash 数组只有在第一个元素被插入到 Hashtable 时才会被分配。
为了避免在许多地方检查这种特殊情况,这里使用了一个小技巧:当 nTableSize 被设置为提示的大小或默认值 8 时,nTableMask 被设置为 0(通常为 nTableSize - 1)。这意味着 hash & ht->nTableMask 的结果总是为 0。
因此,这种情况下的 arHash 数组只需要有一个包含 INVALID_IDX 值的元素(索引为 0),这个特殊数组被称为 uninitialized_bucket,是静态分配的。当执行查找时,我们总是找到 INVALID_IDX 值,这意味着没有找到键(这正是空数组所需要的)。
内存利用率
这一节将说明 PHP 7 中 Hashtable 实现的最重要的几个方面。首先让我们总结一下为什么新的实现使用较少的内存。在这里,我只使用 64 位系统的数字,并且只关注每个元素的大小,忽略 Hashtable 结构体(从渐进的角度看,它的意义不大)。
在 PHP 5.x 中,每个元素需要高达 144 个字节。在 PHP 7 中,这个值降到了 36 个字节,对于 Packed Hashtable 来说这个值是 32 字节。下面这些就是导致这戏的差异的原因:
- zval 不是单独分配的,所以我们节省了 16 个字节的分配开销。
- bucket 不是单独分配的,因此我们节省了另外 16 个字节的分配开销。
- 对于简单的值,zval 比原来要小 16 个字节。
- 不再为了保持元素的顺序而需要 16 个字节维护双向链表,并且这个顺序是隐式的。
- 冲突解决机制链表限制是单向链表,节省了 8 个字节。此外,它现在是一个索引列表,索引被嵌入到了 zval 中,所以实际上我们又节省了 8 个字节。
- 由于 zval 被直接嵌入到 bucket 中,我们不再需要存储一个指向它的指针。由于以前实现的细节问题,我们实际上又节省了两个指针,这又是 16 个字节。
- bucket 不再存储键的长度,这又节省了 8 个字节。然而,如果键实际上是一个字符串而不是整数,那么长度仍然需要存储在
zend_string结构体中。在这种情况下,无非准确的估算内存使用情况,因为zend_string结构体是共享的,对于以前的 Hashtable 来说,如果字符串是非内部(non-interned)的,则需要拷贝字符串。 - 数组包含了冲突解决机制链表的头(基于索引的 head),因此每个元素可以节省 4 个字节。对于压缩数组(Packed Hashtable)来说,根本不需要冲突解决机制链表,在这种情况下,我们又节省了 4 个字节。
然而,上面的总结只是为了更清楚地说明新的 Hashtable 在哪些方面比旧的实现要好。首先,新的 Hashtable 大量的使用了嵌入式(而不是单独分配的)结构体。这会产生什么负面影响吗?
如果你仔细观察本文开头的实际测量结果,你会发现 PHP 7 在 64 位系统上,一个有 100000 个元素的数组占用了 4.00 MiB 的内存。在这种情况下,我们处理的是一个压缩数组(Packed Hashtable),实际上我们预期占用的内存应该是 32 * 100000 = 3.05 MiB。导致这个差异的原因是,在为数组分配内存时,总是以 2 次方幂进行分配。所以当数组包含 100000 个元素时,nTableSize 的值将会是 2 ^ 17 = 131072,最终会分配的内存是 32 * 131072(也就是 4.00 MiB)。
当然,以前的 Hashtable 实现也是使用 2 次方幂进行分配。但是,它只用这种方式分配了一个 bucket 指针数组(其中每个指针是 8 字节)。其它的都是按需分配的。所以在 PHP 7 中,我们浪费了 32 * 31072(0.95 MiB)未使用的内存,而在 PHP 5.x 中,我们只浪费了 8 * 31072(0.24 MiB)。
另一个需要考虑的问题是,如果数组中存储的所有值都不相同,会发生什么情况。为了简单起见,我们假设数组中所有的值都是相同的。因此,我们使用 array_fill 函数替换原本的 range 函数:
$startMemory = memory_get_usage();
$array = array_fill(0, 100000, 42);
echo memory_get_usage() - $startMemory, " bytes\n";
测试的结果如下:
| 32 bit | 64 bit
------------------------------
PHP 5.6 | 4.70 MiB | 9.39 MiB
------------------------------
PHP 7.0 | 3.00 MiB | 4.00 MiB
正如你所看到的,在 PHP 7 中,内存使用情况与 range 的结果一致。由于所有的 zval 都是单独分配的,所以测试结果不可能是不一样的。另一方面,在 PHP 5.x 中,内存使用情况明显降低,这是因为所有的值只使用一个 zval。因此,虽然我们在 PHP 7 上仍然有一些进步,但是现在差距变小了。
一旦我们考虑到字符串键(可能是共享的或非共享的,又或者是非内部的)和复杂值的时候,事情就变得更加复杂了。重点在于 PHP 7 中的数组比 PHP 5.x 占用的内存要少很多,但是在很多情况下,引言中的数字可能过于乐观。
性能
我们已经讨论了很多关于内存使用情况的内容了,所以让我们转到下一个话题,性能。phpng 项目的最终目的不是为了改善内存的使用情况,而是提高性能。内存利用率的提高只是一种手段,因为更少的内存能够提高的 CPU 缓存利用率,从而带来更好的性能。
当然,还有很多其它原因导致新的实现会这么快:首先,减少了内存分配的次数。不管数组元素的值是否共享,我们都为每个元素节省了两次内存分配。内存分配是相当昂贵的操作,这对于性能的提升非常重要。
尤其是现在的数组遍历对缓存更加友好( cache-friendly),因为它现在是对内存进行线性遍历,而不是随机访问(random-access)的链表遍历。
关于性能的话题可能还有很多可以说的,但本文主要的重点是内存的使用情况,所以我不会在这里进一步详述。
总结
就 Hashtable 的实现而言,PHP 7 无疑是向前迈进了一大步,很多无用的开销现在都已经被解决了。
因此,问题是:接下来我们该怎么办?在前面我已经提到的一个想法是,在整数键呈递增的情况下使用「fully packed」结构,这意味着将使用一个普通的 zval 数组实现,这是我们在不开始专门研究统一类型数组的情况下所能做到的最好的事情。
也许还有别的方向可以去尝试一下。例如,将哈希冲突解决机制从拉链法改成开放寻址法(例如使用 Robin Hood probing),在内存使用(没有冲突解决机制链表)和性能(更好的缓存效率,取决于算法的细节)方面都可能会更好。然而,开放寻址法相对来说很难跟保持数组元素顺序的需求结合起来,所以这个想法在实际情况中并不可行。
另一个想法是将 bucket 结构体中的 h 和 key 字段组合起来。整数键只使用 h 字段,字符串键也会在 key 中存储哈希值。然而,这可能会对性能产生不利的影响,因为获取哈希值将需要额外的内存间接寻址。
最后我想说的是,PHP 7 不仅改进了 Hashtable 的内部实现,而且还改进了相关的调用 API。在此之前,我经常不得不查看如何使用 zend_hash_find 这样简单的操作,特别是需要多少个间接级别(提示:3 个)。在 PHP 7 中,只需要编写 zend_hash_find(ht, key),就可以得到一个 zval *。总的来说,我发现为 PHP 7 编写扩展程序变得更加愉快了。
希望我能够为你提供一些对于 PHP 7 的 Hashtable 内部实现的见解。也许我还会写一篇关于 zval 的后续文章。我已经在这篇文章中提到了一些不同之处,但关于这个话题还有很多可以说的。