前言
首先需要向广大的读者道歉,上周因为工作的原因导致这篇文章迟迟没有完成;在这里我也要感谢大家的耐心等待,希望你们会喜欢本系列 :)
在上一篇中,我添加了一些功能代码,并对已有的部分功能代码做了些许优化,这直接导致了性能下降,但这是必要的性能损失,因为fuzzer每次做迭代都必须要考虑到代码覆盖率的问题,我希望接下来的优化能准确的识别并抛弃较差的编译后的样本,我管这叫“进化!!”
和之前的文章一样,我只会展示重要的代码片段,而跳过一些不相关的代码,如果你想阅读完整的代码的话可以在我的GitHub上找到,并且我已将不同阶段的代码都标上了版本号。
在深入研究遗传算法之前,我们还需要对上次未完成的代码稍作修改,首先就是一些基本的覆盖率问题以及实现方法。
简单而高效的覆盖率实现
上一篇中我们使用了一个简单的方法,就是在执行二进制代码时储存每个被访问到的函数的地址,在尝试对收集到的信息做处理的时候我才意识到我其实不需要那么多信息,虽然执行时函数是从f1() -> f3()还是从f2() -> f3()是有很大区别的,但我还是决定用另一种更简单的方法,对于我们的fuzzer来说,知道哪些函数被至少访问过一次就够了,所以我决定使用set而不是继续在列表中跟踪;还有就是一旦函数中的断点被命中,我就会删除这个断点:
def execute_fuzz(dbg, data, bpmap): trace = set()[...] elif event.signum == signal.SIGTRAP: ip = proc.getInstrPointer() br = proc.findBreakpoint(ip-1).desinstall() proc.setInstrPointer(ip-1) # Rewind back to the correct code trace.add(ip - base - 1)
看到这里有些读者可能会注意到另一些小变化,这是我调了两个小时才发现的bug,调试过程还是很有趣的 :p
为了能快速理解产生bug的原因,我们需要介绍一些关于断点的理论知识,现代计算机体系结构通过软件或硬件实现断点,此处我们使用的并不是硬件断点故不介绍;在x86/x64平台上使用0xCC替换给定地址处指令的第一个操作码来实现插入断点,该指令(0xCC)在执行时将发出SIGTRAP信号,通知调试器暂停执行;因为我们用0xcc替换了原始代码,所以在继续执行程序时就会引发一些问题,理想的情况是当我们继续执行程序时,指令指针回退一个字节,并在执行已保存的原始指令的同时重新插入断点,但是Python-ptrace库并不是这么做的。
某种程度上我已将覆盖粒度从函数级上升到了块级,然后便出现了seg fault,不是找到程序漏洞的那种seg fault,而是调试器的seg fault;试想,用相同的调试器同时调试调试器和调试器中的程序。。。可喜可贺的是,经过几个小时的调试和源码阅读,终于我找到了问题所在和解决办法,就是在指令指针回退一个字节之前删除断点。
之前的版本调试器并没出现seg fault是因为每个函数开始处都有些类似于’nop edx, edi’之类的垃圾代码,而删除这些代码并不影响程序的正常执行。
通过之前对断点的学习,我发现如果在第一次命中断点时将其删除,就会使性能大幅提升。之后我又进行了一些测试,结果令我不是很满意。如果将粒度降低(函数级),无论样本怎样变异,依然只会产生很少的不同的覆盖率值;如果将粒度调高(块级),会导致性能大幅下降;希望性能下降能换来精确度的提升。
优化变异策略 —— 主体思想
覆盖率稳定后,我们就需要一种新的方法来变异样本了。之前的变异策略只有一轮,只变异一轮后的样本被输入程序,由于程序将所有跟踪信息丢弃,没有反馈循环,就算一些变异触发了新的函数,但是并没有产生seg fault,也就没有记录。新的变异策略是一个多阶段的反馈循环,会从根本上解决信息丢失或不记录的问题。
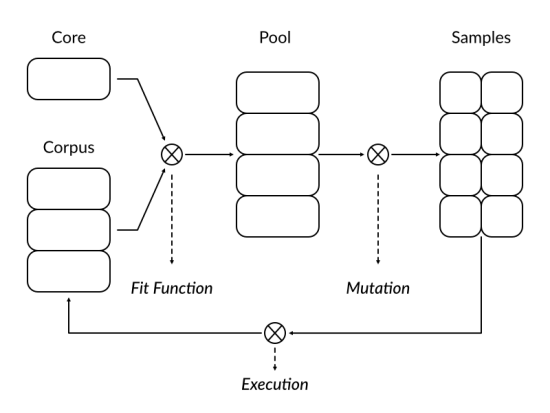
此图是用 Affinity Designer画的,这工具还是挺好用的 :p

我们可以从上图中看到新的变异策略的大致流程;整个循环从fit()函数开始,fit()函数从core和corpus中选择最优样本并放入变异池中,然后对样本池中的样本进行变异形成新的样本体,将其喂给目标程序,当目标程序对单个样本处理完成后,会将样本和跟踪信息一起放回corpus中;当所有变异样本都被处理完成后,则开始新一轮的变异。
总体架构
在Python中,如果想实现多阶段变异,最好是能让我们的变异策略变成一个可迭代的对象。迭代就像for循环一样,在程序中经常出现;在本例中集合就是迭代对象,元素则是每次迭代后喂给程序的内容;在Python中,如果想让类作为迭代对象来使用,测需要_iter_和_next_这两个方法,前者负责初始化迭代器,后者则在每次请求新元素的时候被调用:
class Mutator: def __init__(self, core): # core set of samples self.core = core # Data format = > (array of bytearrays, coverage) self.trace = set() # Currently observed blocks self.corpus = [] # Corpus of executed samples self.pool = [] # Mutation pool self.samples = [] # Mutated samples def __iter__(self): # Initiate mutation round self._fit_pool() self._mutate_pool() return self def __next__(self): if not self.samples: self._fit_pool() self._mutate_pool() global stop_flag if stop_flag: raise StopIteration else: return self.samples.pop()
有两件事需要解释一下:我本来希望迭代器能一直运行,但我不可能让迭代器生成无限多的样本,我也不希望每次请求样本时都会触发迭代器,所以我可以利用_next_提前对几个样本进行变异,当这几个样本耗尽时,触发新的变异。我们必须在迭代器里添加一个全局的stop_flag信号(按下CTRL-C就会停的那种),否则迭代器永远不会停止。
变异策略
这里我们需要明白如何对样本进行变异:
class Mutator: [...] def _mutate_pool(self): # Create samples by mutating pool while self.pool: sample,_ = self.pool.pop() for _ in range(10): self.samples.append(Mutator.mutate_sample(sample))
实现方法很简单,我对变异池中的每个样本都随机生成创建10个不同的样本,我选择10只是因为我喜欢这个数字(并没有做过深入研究),如果你想实现遗传算法的最优变异策略,也可以搜索一些论文。
关于如何变异样本,我决定沿用之前的方法:
@staticmethod def mutate_sample(sample): _sample = sample[:] methods = [ Mutator.bit_flip, Mutator.byte_flip, Mutator.magic_number, Mutator.add_block, Mutator.remove_block, ] f = random.choice(methods) idx = random.choice(range(0, len(_sample))) f(idx, _sample) return _sample
虽说是沿用,但我还是做了一些小改动,当变异只有一轮的时候,我会选择文件中所有字节的百分之几来做变异(但这很激进),但当变异可以迭代时,这种方法可能会使目标程序无法读取样本,所以新版变异策略是随机决定哪些字或字节会产生变异。
你可能会注意到新版的变异方法列表比旧版的更长:bit_flip()和magic_number()保持不变,byte_flip()和bit_flip()有一些细微的变化,但剩下两个变化很大:
@staticmethod def add_block(index, _sample): size = random.choice(SIZE) _sample[index:index] = bytearray((random.getrandbits(8) for i in range(size))) @staticmethod def remove_block(index, _sample): size = random.choice(SIZE) _sample = _sample[:index] + _sample[index+size:]
给定函数的目标由它的名字表示,还有就是如果我们决定将字典添加到fuzzer中,这可以很好的集成字典。
拟合函数
所有遗传算法最主要的就是拟合函数(fit function),它的任务就是为下一阶段的变异选择最优候选样本,拟合函数首先会给所有样本评分,然后再对分数高的样本优先提取;我们的fuzzer会从程序执行过程时捕获的跟踪数据中的两个方面来为样本打分:第一是样本是否能触发程序的新功能;第二是样本是否能达到最高的覆盖率。这两方面并不复杂,但还是需要花些时间研究的:
def _fit_pool(self):
# fit function for our genetic algorithm # Always copy initial corpus print('### Fitting round\t\t')
for sample in self.core:
self.pool.append((sample, []))
print('Pool size: {:d} [core samples promoted]'.format(len(self.pool)))
# Select elements that uncovered new block for sample, trace in self.corpus:
if trace - self.trace:
self.pool.append((sample, trace))
print('Pool size: {:d} [new traces promoted]'.format(len(self.pool)))
# Backfill to 100 if self.corpus and len(self.pool) < 100:
self.corpus.sort(reverse = True, key = lambda x: len(x[1]))
for _ in range(min(100-len(self.pool), len(self.corpus))):
# Exponential Distribution v = random.random() * random.random() * len(self.corpus)
self.pool.append(self.corpus[int(v)])
self.corpus.pop(int(v))
print('Pool size: {:d} [backfill from corpus]'.format(len(self.pool)))
print('### End of round\t\t')
# Update trace info for _, t in self.corpus:
self.trace |= t
# Drop rest of the corpus self.corpus = []我们在三个不同的阶段进行拟合:
第一阶段:我们从原始corpus中提取样本作为对照组,这些样本都是未经任何变异的;我很担心如果我只允许积累变异后的样本会使覆盖率降低。
第二阶段:这一阶段需要提取出那些能触发程序新路径的样本,这个阶段我决定让所有的样本都过一遍
第三阶段:最后一个阶段需要将变异池填满,至少得有100个样本,上一个阶段可能会出现没有足够的样本来发掘新的代码路径,这种情况下我们需要计算丢失了多少样本,并使用其他变异策略从corpus中提取所需要的样本数量,我们按照降序为corpus排序,并使用概率函数选择样本。
解释一下概率函数,如果从corpus中随机选择一个样本,那么排序就没有意义了;然而,如果从0和1之前随机选择两个数并相乘,乘积更可能接近0而不是1;所以具有较高覆盖率的样本更有可能进入下一轮的变异迭代。
最后则是一些收尾工作,收集跟踪信息并删除较差的样本。
下一步要做的事
拟合函数是覆盖引导fuzzer的最后一个重要组件了;完成它并经过简单的测试后,我发现它依然能够在简单的程序用找到bug。不过这个fuzzer还是有很多缺点:效率很差,变异策略也有待提高;但它有一个优点:它很简单,简单到任何人就算从未接触过fuzzer也能读懂它的代码;如果你能读懂这个fuzzer的代码,我想你也可以尝试理解AFL白皮书中的内容。
坦白说我不知道还需要在这个fuzzer里添加什么其他组件,也不知道这个系列会不会有下一篇,事实上我们的fuzzer还有很大的优化空间:优化变异策略,选用执行效率更高的编程语言;这是我的Twitter,如果你有好的想法可以联系我,我很喜欢与读者探讨此类问题 :)
译者言:
因译者水平有限,如若翻译有误,请指正 :)
看雪翻译小组还缺不缺人啊??
原文链接:https://carstein.github.io/2020/05/21/writing-simple-fuzzer-4.html
如有侵权请联系:admin#unsafe.sh