〇、问题引入
上周末在做plaidctf2020-emojidb的时候,发现这道题目的输入输出都是宽字节数据流涉及到字符的编码,而这方面之前一直没有研究。借这道题的机会自己写了几个demo来对字符编码问题进行深入研究。
一、什么是编码系统
我们经常遇到的ASCII、unicode、Big5、GB2312、GBK等等都属于编码系统,他们都包含两方面的内容:字符集和编码方案。字符集是编码系统收录的图形符号集合,比如ASCII码收录了现代英语字母的图形,GB2312收录了常用汉字图形。编码方案是图形和数字之间的映射关系,使得用数字代替图形便于计算机输入输出,比如在ASCII码中,0~31及127共33个是控制字符或通信专用字符,32~126共95个是可显示字符。
二、unicode、UTF、ASCII之间的关系
Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码系统,有UCS-2和UCS-4两种编码规范,其中UCS-2编码长度为2字节,UCS-4是前者的扩展采用4字节编码,因此UCS-4字符集的容量大于UCS-2,在Linux的glibc中对unicode的处理都是UCS-4编码规范。unicode编码系统兼容了ASCII编码系统,因此unicode的前128个编码对应了ascii码。
UTF-8、UTF-16、UTF-32是UTF编码,它的的全称是“Unicode transformation format”,也就是unicode的传输和存储格式。unicode定义了字符和数字之间的映射关系,而UTF则定义了这个数字在内存中的存储方式,所以UTF不是编码系统,这也是UTF经常被误解的地方。
UTF-16用2字节表示一个unicode码,对应的是UCS-2编码规范,同理UTF-32对应的就是UCS-4规范。
UTF-8是unicode的变长编码方式。这么做的原因是,如果对英文字母和标点符号进行unicode编码,那么对应UCS-2和UCS-4只用到了低8位,这种方法显然会浪费一些内存。因此UTF-8对ascii字符还是采用1个字节编码,而对其他符号则采用变长的方式进行编码和存储。UTF-8和unicode的转换关系参考百度百科。
例如中文“今”字的几种编码关系如下:
unicode:"\xca\x4e" UTF-16: "\xca\x4e" UTF-32: "\x00\x00\xca\x4e" UTF-8: "\xe4\xbb\x8a"
我们通常说的unicode其实指的就是UTF-16编码。
总结一下:
unicode和ascii是两种编码系统,且ascii是unicode的子集
UTF是unicode在内存中的存储格式,为了提高内存的使用效率提出了unicode的UTF-8编码方式。
接下来我在deepin环境中以一个可执行文件如何从源代码到最后执行并在控制台显示出字符来解释字符编码是如何被计算机处理的!
三、源文件中的字符表示
以我给出的demo1.c程序为例,它在我的vscode里面采用的是UTF-8编码:
/*
* demo1.c UTF-8
*/
#include <stdlib.h>
#include <unistd.h>
#include <stdio.h>
#include <locale.h>
char *name1 = "今天";
wchar_t *name2 = L"今天";
int main(){
printf("%s\n", name1);
printf("%s\n", name2);
return 0;
}拖到UE里面查看,可以看到都是单字节的UTF-8编码,特别注意方框内标记的是“今”的UTF-8编码。

再将demo1.c转化为UTF-16小端编码,可以看到被扩展为2字节,文件的size也变大了!其中开头的“\xFF\xFE”是UTF-16小端编码文件的magic,“\xCA\x4E”是汉字“今”的UTF-16编码。

可见源代码文件是采用了特定的编码系统来存储程序员写的代码,在Windows平台下的visual studio采用的是ANSI编码,Linux下的源码文件通常为UTF-8编码。这里再次可以见到采用UTF-8对英文字符的unicode进行编码可以节约文件占用的空间!之所以强调英文字符,是因为如果采用UTF-8对其他字符比如汉字进行编码反而不占优势。编译器对源码文件的编码方式是有要求的,例如gcc要求源码文件必须是UTF-8编码,而Windows下的MSVC则支持多种编码方式的源文件并且需要在MSVC的编译选项中加以指定。
四、可执行文件中的静态字符
源码文件经过编译器编译得到可执行文件,字符在可执行文件中的表示分为2类:1、char类型字符的表示 2、wchar_t类型字符的表示。将demo1.c编译之后来观察:
- char类型字符的表示
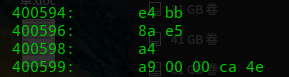
char型变量在内存中占1个字节。name1是指向char类型字符串“今天”的指针,name1指向的0x400594位置的内容是“\xe4\xbb\x8a\xe5\xa4\xa9”,这是“今天”的UTF-8编码,对照前面的UE编辑器里面的内容可以看到,对于char类型的变量,gcc编译器就是把源文件中的编码直接塞到了可执行文件里。


- wchar_t类型字符的表示
wchar_t是char类型的扩展,占用2字节或4字节内存,用于存储超出char范围的字符比如中文。在Linux glibc中wchar_t被定义为4字节变量,用于存储UCS-4字符。demo1中name2为指向wchar_t类型的指针,在给wchar_t类型变量赋值时需要给字符串加上“L”前缀,表示每个字符按照UCS-4格式存储在wchar_t类型的变量中,否则中文字符还是按照UTF-8进行编码。name2指向0x40059c的内容是“\x00\x00\xca\x4e\x00\x00\x29\x59”,这是“今天”的UTF-32编码。


所以gcc编译器在处理wchar_t类型变量的时候,将字符转化为了UTF-32编码然后塞到了可执行文件里。这里解释了为什么文件编码格式对编译器很重要,因为编译器在进行wchar_t类型的编码转换的时候需要知道是从哪一个字符集转换到UTF-32,gcc只能编译UTF-8编码的文件,虽然提供了-finput-charset选项可以指定源文件编码类型,但归根到底也还是将源文件转化成了UTF-8文件,所以gcc知道他要将一个UTF-8编码换成UTF-32的编码,而在visual studio里面则需要在MSVC里面的编译选项中对源文件编码类型进行设置。
总结一下,对于char类型的字符,编译器直接按照源文件中的编码塞到了可执行文件中。对于加“L”前缀的wchar_t类型的字符,编译器将源文件中的编码转化为UTF-32编码塞到可执行文件中。
五、内存里的字符表示
可执行文件被ld加载器映射到了进程地址空间,映射的过程就是复制的过程,因此可执行文件中的静态字符串被加载之后编码方式没有改变。对于使用scanf、wscanf从外部输入的动态存储的字符串,他们在内存里面使用2种编码存储方法:1、原生编码 2、UCS-4编码。
原生编码是输入函数从输入流获取的原生符号编码,他通常是操作系统设置的本地语言编码比如"zh_CN.UTF-8",终端传递给程序的字符编码就是系统的原生编码,数据类型是char。UCS-4编码是把从输入流获取的原生符号编码转换为UCS-4编码也就是UTF-32然后存储到缓冲区,数据类型是wchar_t。
六、终端输入输出模型
终端扮演的角色是:接收程序输出流的数据,并按照终端的本地编码格式解释输出流,将最终的解释结果显示在屏幕上。在输入的过程中,把显示在终端上的字符按照终端的本地编码格式编码并通过输入流传递给程序。这里的输入输出流是相对于程序而言的。后面字符解释字符的动态存储和输出都是基于此模型。

七、字符的动态存储
对于输入函数scanf和wscanf,他们从输入流获取的原生字符编码按照何种方式存储在缓冲区,是由他们的格式化字符串决定的。这两个函数在功能上是重叠的,格串为"%s"表示向缓冲区输出原生字符编码,格串为"%ls"表示向缓冲区输出转换后的UCS-4编码。下图展示了使用不同格串时输入函数内部发生的编码转换过程:

其中mb表示原生字符编码,wb表示UCS-4编码。原生编码转换为UCS-4是通过glibc库函数mbrtowc()完成的,UCS-4转换为原生编码通过wcrtomb()库函数完成。发生编码转换的前提是要直到操作系统的本地语言编码是什么,这样才能建立原生编码和UCS-4编码的映射,因此在进行2、 3、 4这样的操作之前要调用setlocale在运行时告诉转换编码函数,本地编码是什么。例如:
/**demo1.c UTF-8**/
#include <stdlib.h>
#include <unistd.h>
#include <stdio.h>
#include <locale.h>
wchar_t buf[10];
int main(){
setlocale(LC_ALL, "zh_CN.UTF-8");
scanf("%ls", buf);
return 0;
}
"\xca\x4e\x00\x00\x29\x59\x00\x00"是终端输入字符"今天"的UCS-4编码。通过setlocale(LC_ALL, "zh_CN.UTF-8"),scanf就知道他要把输入流过来的UTF-8编码转换成UCS-4。
七、字符的输出
输出函数printf和wprintf,他们获得指向字符缓冲区的指针,输出字符缓冲区的内容。printf和wprintf的功能也是重叠的,对于要输出的字符串按照什么类型存储是由格式化串解释的,"%s"表示要输出的字符串按照原生编码存储,数据类型是char,"%ls"表示要输出的字符串按照UCS-4存储,数据类型是wchar_t。下图展示了使用不同格串时输出函数内部发生的编码转换过程:

输出函数最终的输出编码都是原生编码,因为终端只负责解析本地编码类型的编码,如果输出流里面的不是原生编码,那么终端就无法正确显示结果。和输入函数一样,当发生编码转换的时候程序必须被运行时告知本地编码的类型,这个步骤也是由setlocale函数完成的,例如:
/** demo2.c UTF-8 **/
#include <stdlib.h>
#include <unistd.h>
#include <stdio.h>
#include <locale.h>
char *name1 = "今天";
wchar_t *name2 = L"今天";
int main(){
printf("before setlocale: %ls\n", name2);
setlocale(LC_ALL, "zh_CN.UTF-8");
printf("after setlocale: %ls\n", name2);
return 0;
}
在setlocale之前printf不能正常显示,因为此时printf将"今天"的UCS-4编码按照C语言内置的最小公共编码来转换,在没有显式地设置本地编码的时候,这个选项是默认的。第二个printf才将UCS-4正确地转化为了UTF-8。
八、两个实例
我用上面总结得到的结论来解释两个在实际编程过程中遇到的问题。
- 输出函数格式化串少加了一个"l"引发的错误
/** demo3.c UTF-8 **/
#include <wchar.h>
#include <unistd.h>
#include <stdio.h>
#include <locale.h>
char *name1 = "中文";
wchar_t *name2 = L"中文"; //UCS-4
int main(){
setlocale(LC_ALL, "zh_CN.UTF-8");
wprintf(L"%s\n", name2);
return 0;
}
程序的意图是输出UCS-4编码的"中文",可以看到已经设置了本地编码方式,但结果却是"-N"。
查阅Linux接口手册得到解释:wprintf解析格串时遇到"%s"表示要输出的字符串是一个char类型的本地编码字符串,此时会对每个本地编码字符调用mbrtowc()库函数,按照setlocale指定的本地编码方式将本地编码转化为wchar_t类型的UCS-4编码,再将UCS-4编码加入输出流,这里指定的本地编码类型是zh_CN.UTF-8编码,因此转换过程是UTF-8--->UTF-32。



在这里name2指向的地址存放着"中文"二字的wchar_t类型的UCS-4字符,也即是"\x2d\x4e\x00\x00\x87\x65\x00\x00",其中"\x2d"和"\x4e"是UTF-8格式的字符 "-"和"N",对每个本地编码字符调用mbrtowc()得到L"-"、L"N"然后加入到输出流,后面因为\x00而截断。而"-"和"N"的UTF-32和UTF-8编码相同,因此终端输出 “-N”。
- 输入函数格式化串少了"l"引发的错误
/*
* demo4.c UTF-8
*/
#include <wchar.h>
#include <unistd.h>
#include <stdio.h>
#include <locale.h>
char buf[10];
int main(){
setlocale(LC_ALL, "zh_CN.UTF-8");
scanf("%s", buf);
wprintf(L"buffer: %ls\n", buf);
return 0;
}
程序的意图是通过scanf保存一个UCS-4字符串,通过wprintf打印。输入"今天"却显示了乱码。
使用gdb调试观察buf的内容为"\xe4\xbb\x8a\xe5\xa4\xa9",这是"今天"的UTF-8编码,说明scanf在"%s"的作用下存储了原生编码,并未将其转化为UCS-4。

那么接下来发生的事情就很明显了,wprintf把buf按照UCS-4来解析,试图完成UCS-4到UTF-8的转换,通过pwntools来观察程序的输出:

最终"\xe4\xbb\x8a\xe5"被解析成"\x7f",显示了问号;"\xa4\xa9\x00\x00"被解析成"\xea\xa6\xa4",显示"ꦤ"。
把scanf的格式串改正为"%ls"或者把wprintf的格串改为"%s"均能得到正确输出。

九、总结

为什么会出现编码问题?是因为程序内部发生了隐式的编码转化。为什么会有隐式编码转换?是因为glibc引入了wchar_t数据类型用来专门存放UCS-4编码,一旦用到wchar_t数据类型,那么在输入方向就需要将原生编码转换为UCS-4,在输出方向就需要UCS-4转换为原生编码。所以需要同时从输入和输出两个方向考虑才能避免出现编码问题。
如有侵权请联系:admin#unsafe.sh