上周也是个大新闻不断的一周。AutoGPT霸榜,Musk支持完暂停AI声明就回去偷偷研究,可商用LLM Dolly2发布,不同于现有产图扩散模型的新的模型“一致性模型”…
下面让我回顾一下上一周的AI大新闻。
上上一周见此:
AutoGPT开始了它的爆火全网之旅。该工具由 SigGravitas 开发,4月1日左右公布,短短几天内已经有了几千用户。而这周,它引爆了整个推特,无数基于他的工具在开发&发布。
AutoGPT是一个实验性的开源应用,展示了GPT-4语言模型的能力。它是一个自主的人工智能代理,可以将LLM的 "思想 "串联起来,实现你设定的任何目标。它不需要人类的提示或干预,而且可以自我提示。它是GPT-4完全自主运行的首批范例之一。其原理如下:

更具体地来说:AutoGPT通过设计精妙的prompt将操作任务转变为命令,让GPT-4选择并执行。这些命令包括谷歌搜索、浏览网站、读写文件等。发送问题给GPT-4后,它会根据COMMAND选择最佳方式获得答案,并给出所需参数。AutoGPT依据返回结果执行相应操作。
GITHUB地址:https://github.com/Significant-Gravitas/Auto-GPT
当然如果你不想自行安装,可以使用web端的服务 AgentGPT
类似于AgentGPT的仿品还有:
Cognosys: https://www.cognosys.ai/
以及 Godmode: https://godmode.space
这两者都不需要OpenAI KEY即可免费使用。
其中最引人注目的一点是该体系包含了商汤最新研发的语言大模型“商量SenseChat”。
据悉,作为千亿级参数的自然语言处理模型,“商量SenseChat”使用大量数据训练,并充分考虑了中文语境,能够更好地理解和处理中文文本。活动现场,“商量SenseChat”展示了出色的多轮对话和超长文本的理解能力。

此外商汤还公布了各种AI文生图创作、2D/3D数字人生成、大场景/小物体生成等一系列生成式AI模型及应用:
“秒画SenseMirage”文生图创作平台,展现了光影真实、细节丰富、风格多变的强大的文生图能力,可支持6K高清图的生成;客户还可根据自身需求训练生成模型。
“如影SenseAvatar”AI数字人视频生成平台,仅需一段5分钟的真人视频素材,就可以生成出来声音及动作自然、口型准确、多语种精通的数字人分身。
“琼宇SenseSpace”和“格物SenseThings”3D内容生成平台,可以高效低成本生成大规模三维场景和精细化的物件,为元宇宙、虚实融合应用打开新的想象空间。

OpenAI宣布了一项漏洞赏金计划。提交漏洞最低200美元,最高2万美元奖励。Open AI希望通过这种全民找漏洞的方式,将ChatGPT等产品的风险输出、安全隐患、数据隐私等问题降至最低,从而为人们提供更安全、可靠的AI服务。
赏金计划地址:https://bugcrowd.com/openai
Dolly 2.0宣布发布。
Dolly 2.0是一款基于EleutherAI的pythia模型系列的大型语言模型,拥有1200亿个参数。Dolly 2.0的训练代码、数据集和模型权重等均已开源,与羊驼模型最大的区别在于”允许进行商业用途“。
同时,用于训练的数据集“databricks-dolly-15k”包含了由数千名公司员工生成的15,000条记录,这被认为是大型语言模型首个开源的、由人类生成的命令数据集。该数据集在知识共享许可下公开发布,同样可用于包括商业在内的各种用途,可以自由使用、修改和扩展。
数据集地址:
https://github.com/databrickslabs/dolly/tree/master/data
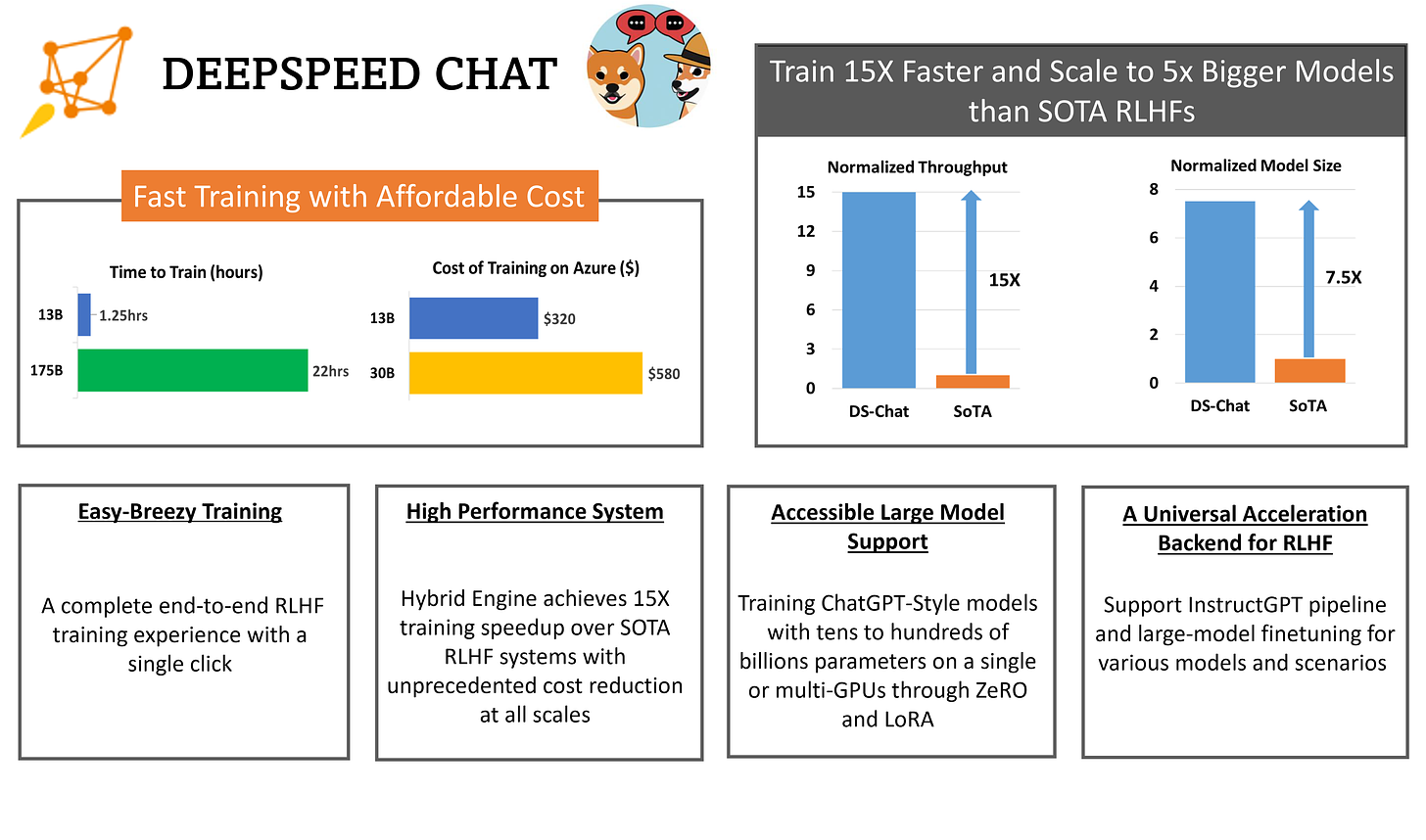
https://github.com/microsoft/DeepSpeed/tree/master/blogs/deepspeed-chat

Deep Speed Chat基于微软的Deep Speed深度学习优化库构建,具备训练和强化推理等功能,采用了RLHF(基于人工反馈的强化学习)技术,能将训练速度提高15倍以上,同时显著降低成本。一个具有1300亿参数的类ChatGPT模型,仅需1.25小时即可完成训练。
OpenAI发布了一种新的图片生成模型:Consistency Models一致性模型。一致性模型是OpenAI提出的一个新的生成模型系列,无需对抗性训练就能产生高质量的样本。它们是基于在同一数据的不同版本之间强制执行一致性的想法,比如噪声和去噪的图像1。它们可以被训练成预训练的扩散模型的简化版或独立的生成模型。它们可以实现比扩散模型更快的采样速度,但代价是一些质量的下降。
这是OpenAI提出的一个新的生成模型系列,无需对抗性训练就能产生高质量的样本。它们是基于在同一数据的不同版本之间强制执行一致性的想法,比如噪声和去噪的图像。它们可以被训练成预训练的扩散模型的简化版或独立的生成模型。

据称,它们可以实现比Midjourney、DALL- E、Stable Diffusion等采用的扩散模型更快的采样速度,但代价是一些质量的下降。
论文地址:https://arxiv.org/abs/2303.01469
GITHUB地址:https://github.com/openai/consistency_mode
“知海图AI”的训练基于面壁智能自主研发的 CPM企业级大模型 与 ModelForce大模型系统。详细见此。
据《华尔街日报》报道,半个月前还在号召停止AI研究的 elonmusk 被发现成了一家研究AI的公司“X.AI”。X.AI在内华达州注册成立,专注于人工智能研究和开发。

关于号召停止开发AI的新闻见此:
值得注意的是这家公司同样属于musk的新公司“X”旗下。而现在已知这个神秘的X公司包含了Musk的所拥有所有公司,推特、SpaceX、特斯拉、Neuralink...
而且最近还爆出来,Musk买了上万个GPU用于训练AI,这可真是...

在麻省理工学院举办的“The Future of Business with AI”活动中,OpenAI CEO Sam表示,OpenAI现在没有训练GPT-5。
另外关于公开暂停训练比GPT-4更强大的公开信,Sam说到,在正式推出GPT-4之前,Open AI用了6个月的时间优化其安全性,并认为这封信语焉不详,对于如何暂停,应该停在哪里无详细说明,参考价值有限。
现场视频:
最后:虽然与AI无关,但请让我展示一下参与 #ETHGLOBAL 时体验的 Worldcoin orb

如果这篇有帮助,请订阅转发,也可以fo我的推特。我将带给你更多关于Web3,Layer2,AI,以及日本相关咨询:
如有侵权请联系:admin#unsafe.sh