
本周相对来说比较平淡,更多的厂家进入了LLM赛道,Google在产品上努力追赶OpenAI,SnapChat公开了自己的聊天AI BOT。
下面让我回顾一下上一周的AI大新闻。
上上周见此:
4月17日
昆仑万维推出千亿级大语言模型“天工”并开始内测。

由昆仑万维与AI团队奇点智源合作研发的“天工”是一个与ChatGPT相媲美的双千亿级大型语言模型,同时也是昆仑万维继AI绘画产品“天工巧绘”之后的又一款创新生成式AI产品。昆仑万维在2022年12月发布了AIGC全系列算法与模型,涵盖了图像、音乐、文本、编程等多模态AI内容生成能力。据昆仑万维表示,“天工”的当前版本最高支持1万字以上的文本对话,能实现20轮次以上的用户交互。
据称整个项目已投入数亿元人民币,组建了数百人的研发团队,未来将继续加大投入。
内测地址:
4月18日
Meta发布DinoV2。

https://twitter.com/MetaAI/status/1648038974290808836
DINOv2是一种新的用于训练具有自监督的高性能计算机视觉模型(自监督是指模型从没有标记的数据中学习,而不需要人类的注释)。DINOv2在几个计算机视觉基准上取得了最优异的结果,如图像分类、物体检测和分割,这是由于DINOv2基于一种新颖的对比学习方法,鼓励模型关注图像的突出区域而忽略背景。它可以从任何图像集合中学习,不需要针对不同的任务进行微调。
演示地址:https://dinov2.metademolab.com/
论文:https://arxiv.org/abs/2304.07193
GITHUB:https://github.com/facebookresearch/dinov2
4月19日
https://twitter.com/_akhaliq/status/1650308865555148800?s=20
Aydar Bulatov等人发布了一种利用RMT将Transformer扩展到100万+token的技术。

该技术报告介绍了应用递归存储器来扩展BERT的上下文长度,BERT是自然语言处理中最有效的基于Transformer的模型之一。通过利用递归记忆转化器架构,他们成功地将该模型的有效语境长度增加到了前所未有的200万条,同时保持了较高的记忆检索精度。该方法允许存储和处理局部和全局信息,并通过使用递归法使信息在输入序列的各段之间流动。
在推理过程中,该模型有效地利用了总长度为2,048,000 tokens的4,096个片段的内存--大大超过了报告的转化器模型的最大输入大小(CoLT5的64K tokens,以及GPT-4的32K tokens)。在他们的实验中,这种增强使基本模型的内存大小保持在3.6GB。
论文地址:https://arxiv.org/abs/2304.11062
GITHUB:https://github.com/booydar/t5-experiments/tree/scaling-report
4月20日

https://twitter.com/cryptonerdcn/status/1648740916071657472?s=20
著名产图工具Stable Diffusion的厂商Stability-AI宣布他们也搞了个LLM--StableLM。这是一个可以在不同领域和任务中产生稳定和一致的文本的语言模型。Alpha版本有30亿和70亿个参数但性很好(GPT-3有1750亿个参数),后续还有150亿到650亿个参数的模型。 “开发者可以自由检查、使用和改编我们的StableLM基础模型,用于商业或研究目的,但必须遵守CC BY-SA-4.0许可证的条款”(需要注意的一点是,Base Model虽然是Creative Commons license,但Fine-tuned是Non-Commercial Creative Commons license,即无法商用。)。
GITHUB: https://github.com/stability-AI/stableLM/
同日,Snapchat向全球所有用户推出了人工智能聊天机器人功能。
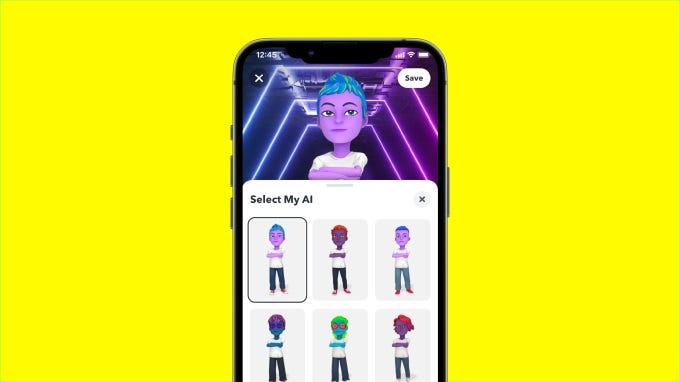
这个名为Snapbot的聊天机器人允许用户与一个人工智能代理进行对话,它可以回答问题、讲笑话、玩游戏和发送快照。Snapbot还可以从用户的喜好和行为中学习,并会根据用户的兴趣偶尔发送快照给用户。Snapchat声称,Snapbot不是为了取代人与人之间的互动,而是为了加强人与人之间的互动,使其更加有趣和吸引人。Snapbot由一个深度神经网络驱动,可以生成自然语言回应和图像。Snapchat称,Snapbot符合隐私和数据保护法,用户可以在任何时候选择退出该功能。
https://twitter.com/Snapchat/status/1648748425494790144?s=20
4月21日
Google的AI Bard开放写代码能力,支持20种语言,并且可以Debug。
https://twitter.com/JackK/status/1649403850703650816?s=20



同日,复旦大学自然语言处理实验室推出了全新的MOSS模型,成为国内首个插件增强型类ChatGPT开源大型语言模型。
MOSS是一款支持中英双语及多种插件的开源对话语言模型。moss-moon系列模型拥有1600亿参数,在FP16精度下可在单张A100/A800或两张3090显卡上运行;在INT4/8精度下,可在单张3090显卡上运行。MOSS 基座语言模型在约七千亿中英文以及代码单词上预训练得到,后续经过对话指令微调、插件增强学习和人类偏好训练具备多轮对话能力及使用多种插件的能力。
MOSS模型源自复旦大学自然语言处理实验室的邱锡鹏教授团队,其名称来源于电影《流浪地球》中的AI。
GITHUB:https://github.com/OpenLMLab/MOSS
如果这篇有帮助,请订阅转发,也可以fo我的推特。我将带给你更多关于Web3,Layer2,AI,以及日本相关咨询:
如有侵权请联系:admin#unsafe.sh